

AMD melalui rilis ROCm 7.0 memperkenalkan Instinct MI355X, GPU yang dirancang untuk mendorong performa Large Language Model (LLM) training dengan efisiensi tinggi. Fokusnya adalah token throughput (tokens/gpu/s) sebagai metrik utama untuk skala besar, baik pada PyTorch maupun JAX frameworks.

Integrasi Software: Primus & MaxText
- Primus Framework:
- Mendukung backend TorchTitan & Megatron-LM.
- Primus-Turbo mempercepat model Transformer di GPU MI355X.
- Modular & reproducible configuration untuk memudahkan deployment.
- JAX MaxText Docker:
- Prebuilt environment dengan JAX, XLA, ROCm libraries.
- Memudahkan scaling & eksperimen tanpa konfigurasi kompleks.

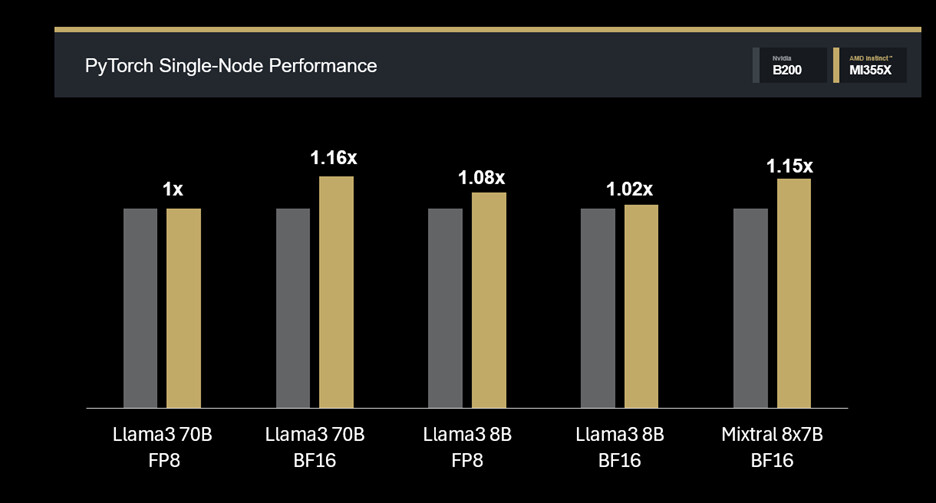
Benchmark PyTorch (Single-Node)
- Llama3 70B FP8: 1.0X (paritas baseline).
- Llama3 70B BF16: 1.16X.
- Llama3 8B FP8: 1.08X.
- Llama3 8B BF16: 1.02X.
- Mixtral 8x7B FP16: 1.15X. ➡️ MI355X menunjukkan throughput lebih tinggi dibanding GPU B200 pada sebagian besar model.


Benchmark JAX MaxText (Single-Node)
- Llama3.1 70B FP8: 1.11X.
- Llama3.1 8B FP8: 1.07X.
- Mixtral 8x7B FP16: 1.00X (paritas). ➡️ MI355X unggul pada dense models, mendekati parity pada MoE workloads.
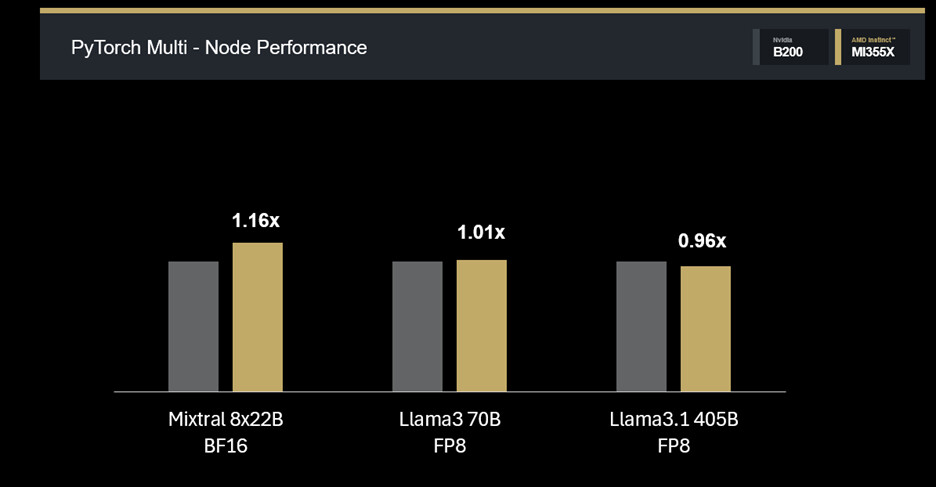
Multi-Node Scaling
- Mixtral 8x22B BF16: 1.14X (4-node Primus-Megatron).
- Llama3 70B FP8: 1.01X (paritas, 4-node).
- Llama3.1 405B FP8: 0.96X (8-node). ➡️ MI355X mampu scale-out dengan baik, tetap kompetitif terhadap B200.
Implikasi
- Single-node: performa tinggi untuk dense & MoE models.
- Multi-node: skalabilitas kuat untuk distributed training.
- Ekosistem: ROCm 7.0 + Primus + MaxText → foundation kokoh untuk riset & pengembangan AI generasi baru.
Sumber: AMD ROCm Blog








