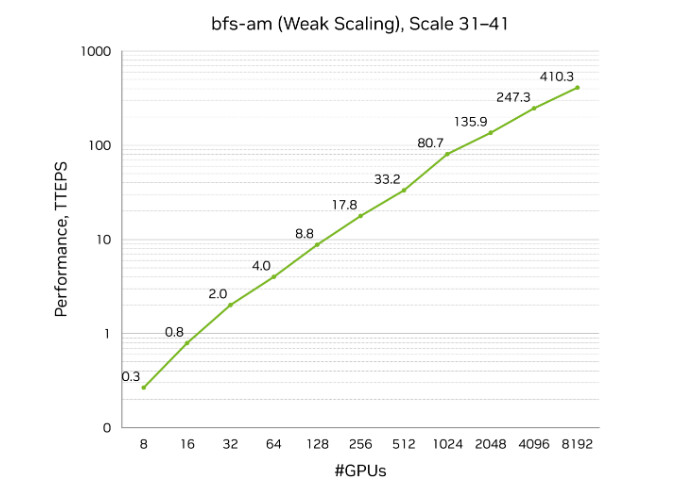
NVIDIA kembali mencetak pencapaian besar di dunia komputasi performa tinggi. Perusahaan ini mengumumkan bahwa klaster GPU NVIDIA H100 yang berjalan di platform CoreWeave AI Cloud berhasil memecahkan rekor benchmark Graph500, dengan performa mencapai 410 triliun traversed edges per second (TEPS). Hasil tersebut menempatkan sistem ini di peringkat pertama pada Graph500 Breadth-First Search (BFS) edisi ke-31.
Pengujian dilakukan pada klaster komputasi terakselerasi yang dioperasikan di pusat data CoreWeave di Dallas. Dalam pengujian tersebut, sistem memanfaatkan 8.192 GPU NVIDIA H100 untuk memproses graf berskala masif dengan 2,2 triliun vertex dan 35 triliun edge. Performa ini tercatat lebih dari dua kali lipat dibandingkan solusi lain yang ada di daftar Graph500, termasuk sistem yang dioperasikan oleh laboratorium nasional.
Efisiensi Jadi Kunci Keunggulan
Untuk menggambarkan skala performanya, NVIDIA memberikan ilustrasi sederhana. Jika setiap manusia di Bumi memiliki 150 koneksi pertemanan, maka akan terbentuk graf sosial dengan sekitar 1,2 triliun edge. Dengan performa yang dicapai klaster NVIDIA dan CoreWeave, seluruh hubungan tersebut dapat ditelusuri hanya dalam waktu sekitar tiga milidetik.
Namun, kecepatan bukan satu-satunya keunggulan. Efisiensi sistem menjadi sorotan utama. Entri lain di jajaran 10 besar Graph500 umumnya menggunakan sekitar 9.000 node, sementara sistem NVIDIA hanya memerlukan sedikit di atas 1.000 node. Hasilnya adalah efisiensi biaya hingga tiga kali lebih baik dibandingkan solusi sekelas.

Kekuatan Full-Stack NVIDIA
Keberhasilan ini dicapai berkat pemanfaatan penuh ekosistem teknologi NVIDIA, mulai dari platform CUDA, jaringan Spectrum-X, GPU H100, hingga pustaka active messaging terbaru. Pendekatan full-stack ini memungkinkan peningkatan performa signifikan sekaligus menekan kebutuhan perangkat keras.
Pencapaian tersebut menunjukkan bahwa platform komputasi NVIDIA siap memperluas akses terhadap akselerasi beban kerja berskala besar, khususnya untuk workload graf yang bersifat sparse dan tidak teratur, di samping beban kerja padat seperti pelatihan AI.
Mengapa Graph500 Penting
Graf merupakan struktur data fundamental dalam teknologi modern. Media sosial, aplikasi perbankan, hingga sistem keamanan siber bergantung pada graf untuk merepresentasikan hubungan antar data. Dalam konteks ini, setiap entitas direpresentasikan sebagai vertex, sementara hubungan antar entitas menjadi edge.
Benchmark Graph500 BFS telah lama menjadi standar industri karena mengukur kemampuan sistem dalam menavigasi graf yang kompleks dan tidak teratur dalam skala besar. Skor TEPS yang tinggi menandakan kualitas interkoneksi antar node, bandwidth memori, serta kemampuan perangkat lunak dalam memanfaatkan arsitektur sistem secara optimal. Dengan kata lain, ini adalah ukuran seberapa cepat sebuah sistem dapat “berpikir” dan mengaitkan informasi.
GPU Mengubah Cara Pemrosesan Graf
Selama bertahun-tahun, pemrosesan graf berskala besar didominasi oleh arsitektur CPU. Namun, seiring pertumbuhan data hingga triliunan edge, pendekatan ini menghadapi hambatan serius akibat lalu lintas data antar node yang padat.
NVIDIA merombak pendekatan tersebut dengan solusi GPU-only. Melalui pemanfaatan InfiniBand GPUDirect Async dan antarmuka pemrograman NVSHMEM, sistem memungkinkan active messaging langsung antar GPU, tanpa melibatkan CPU. Pendekatan ini memaksimalkan paralelisme dan bandwidth memori GPU H100, sekaligus menghilangkan bottleneck tradisional.
Dampak Besar bagi HPC
Terobosan ini membawa implikasi luas bagi dunia high-performance computing (HPC). Bidang seperti dinamika fluida, prakiraan cuaca, hingga keamanan siber menggunakan pola komunikasi dan struktur data yang serupa dengan graf berskala besar. Selama puluhan tahun, beban kerja ini bergantung pada CPU di skala ekstrem.
Hasil NVIDIA di Graph500, ditambah dua entri lain di 10 besar, menegaskan bahwa pendekatan berbasis GPU kini siap menjadi fondasi baru HPC. Dengan orkestrasi penuh antara komputasi, jaringan, dan perangkat lunak, performa superkomputer kini dapat dihadirkan melalui infrastruktur komersial yang tersedia luas.
Sumber: NVIDIA Blog








