
Google Perkenalkan Generasi Kedelapan Tensor Processor Unit (TPU) Kustomnya

Dalam ajang Google Cloud Next, Google secara resmi memperkenalkan generasi kedelapan dari Tensor Processor Unit (TPU) kustom mereka. Dirancang khusus untuk menghadapi era agen kecerdasan buatan (AI), Google kini memecah arsitekturnya menjadi dua cip yang dibangun untuk tujuan berbeda: TPU 8t untuk pelatihan (training) dan TPU 8i untuk inferensi.
Dirancang melalui kemitraan erat dengan Google DeepMind, kedua cip ini diciptakan untuk menenagai superkomputer kustom Google dan menangani beban kerja AI yang paling menuntut. Menurut Google, inovasi ini adalah puncak dari pengembangan selama lebih dari satu dekade untuk beradaptasi dengan skala arsitektur model AI yang terus berkembang.


Dua Cip untuk Kebutuhan Berbeda
Mengingat siklus pengembangan perangkat keras jauh lebih lama daripada perangkat lunak, Google telah mengantisipasi lonjakan permintaan untuk inferensi dari pelanggan seiring dengan penerapan model AI frontier dalam skala besar. Oleh karena itu, generasi kedelapan ini menghadirkan spesialisasi:
TPU 8t: Pusat Tenaga Pelatihan Model
TPU 8t dibangun untuk memangkas siklus pengembangan model mutakhir dari hitungan bulan menjadi hanya beberapa minggu saja. Cip ini memberikan peningkatan kinerja komputasi hingga 3x lipat per pod dibandingkan generasi sebelumnya.
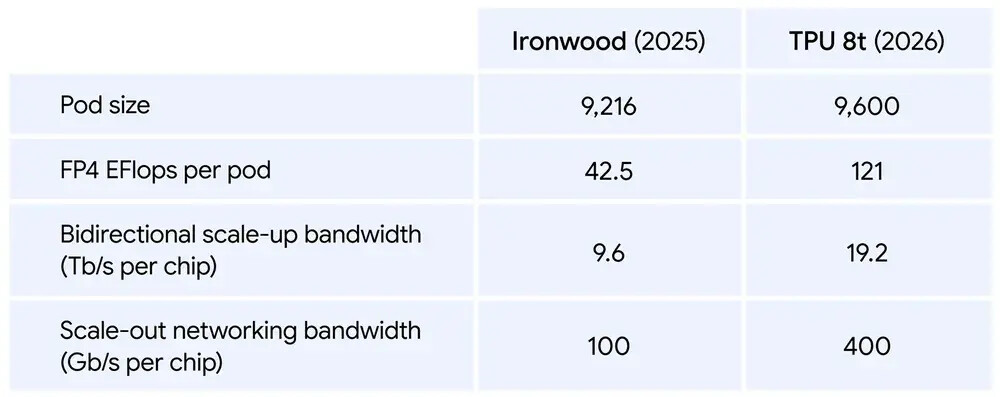
- Skala Masif: Satu superpod TPU 8t kini dapat menskalakan hingga 9.600 cip dan dua petabyte memori bandwidth tinggi bersama, memberikan 121 ExaFlops komputasi.
- Pemanfaatan Maksimal: Mengintegrasikan akses penyimpanan 10x lebih cepat dan TPUDirect untuk menarik data langsung ke TPU.
- Skala Hampir Linear: Berkat jaringan Virgo baru yang dipadukan dengan JAX dan perangkat lunak Pathways, TPU 8t dapat menyediakan penskalaan hampir linier untuk hingga satu juta cip dalam satu klaster logis.
- Keandalan Tinggi: Direkayasa untuk menargetkan lebih dari 97% “goodput” (ukuran waktu komputasi yang produktif) melalui deteksi dan perutean ulang otomatis di sekitar tautan yang rusak tanpa mengganggu pekerjaan (Optical Circuit Switching).
TPU 8i: Jagoan Inferensi Tanpa Jeda
Di era agen AI, pengguna mengharapkan respons yang cepat saat mendelegasikan tugas. TPU 8i dirancang untuk menangani pekerjaan iteratif dan kolaboratif dari banyak agen khusus dengan menekan latensi serendah mungkin.
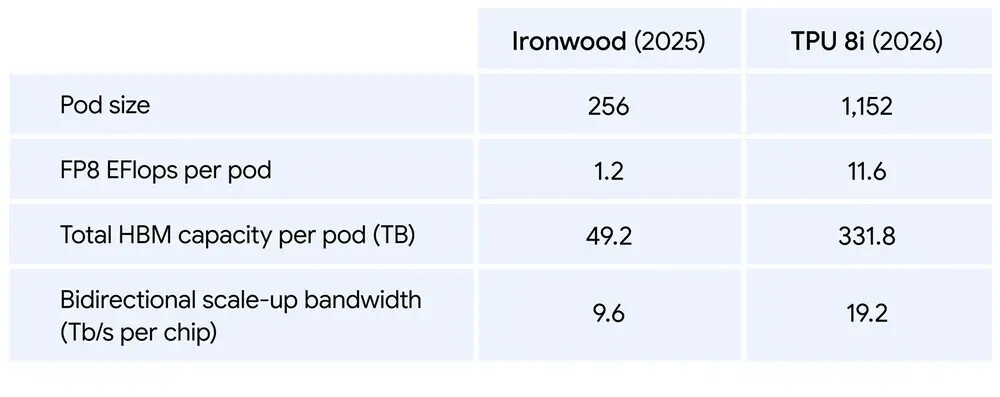
- Mendobrak Dinding Memori: Memasangkan memori bandwidth tinggi sebesar 288 GB dengan SRAM on-chip sebesar 384 MB (3x lebih besar dari generasi sebelumnya).
- Efisiensi Tenaga Axion: Google menggandakan host CPU fisik per server, beralih ke CPU kustom mereka sendiri yang berbasis arsitektur Arm, yakni Axion.
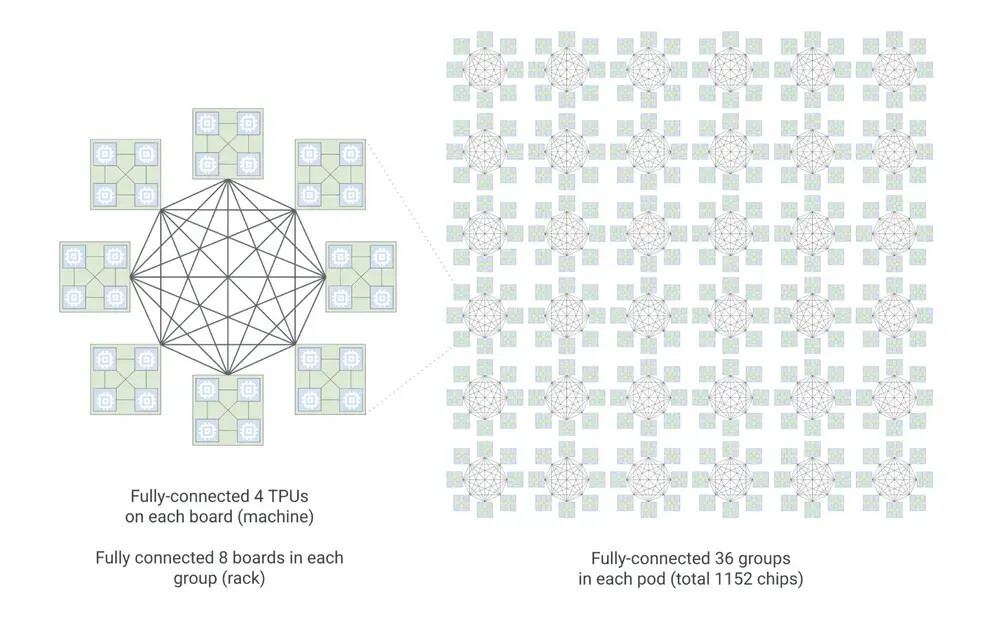
- Penskalaan Model MoE: Untuk model Mixture of Expert (MoE) modern, cip ini menggandakan bandwidth interkoneksi menjadi 19,2 Tb/s. Arsitektur Boardfly baru juga memangkas diameter jaringan maksimum hingga lebih dari 50%.
- Eliminasi Lag: Mesin Akselerasi Kolektif (CAE) on-chip baru memindahkan operasi global, mengurangi latensi pada cip hingga 5x lipat.
Secara keseluruhan, inovasi pada TPU 8i ini diklaim mampu memberikan rasio performa-per-dolar 80% lebih baik dibandingkan dengan generasi sebelumnya.

Efisiensi Daya Berada di Garis Depan
Di pusat data modern saat ini, pasokan listrik adalah kendala utama. Untuk mengatasi hal ini, Google telah mengoptimalkan efisiensi di seluruh tumpukan teknologi mereka.
TPU 8t dan TPU 8i memberikan performa-per-watt hingga dua kali lebih baik dibandingkan generasi ketujuh (Ironwood). Keduanya juga didukung oleh teknologi pendingin cair (liquid cooling) generasi keempat dari Google yang mampu mempertahankan kepadatan performa yang tidak dapat ditangani oleh sistem pendingin udara biasa.
Baik TPU 8t maupun TPU 8i mendukung ekosistem framework populer seperti JAX, MaxText, PyTorch, SGLang, dan vLLM secara native. Kedua cip super mutakhir ini dijadwalkan akan tersedia secara umum pada akhir tahun ini sebagai bagian dari AI Hypercomputer milik Google Cloud.
Sumber: Google








