Seiring dengan kedaulatan data dan performa komputasi yang kini menjadi pembeda strategis bagi perusahaan yang mengadopsi kecerdasan buatan (AI), permintaan akan infrastruktur AI pribadi di lokasi (on-premises) terus melonjak.

Merespons pergeseran tren tersebut, inovator solusi komputasi, jaringan, dan penyimpanan QNAP Systems, Inc. hari ini secara resmi memperkenalkan QAI-h1290FX. Ini adalah server penyimpanan Edge AI generasi berikutnya yang dirancang khusus untuk memberdayakan penerapan pribadi Model Bahasa Besar (Large Language Models/LLM), mesin pencari Retrieval-Augmented Generation (RAG), dan berbagai aplikasi AI generatif.

Perangkat Keras Kelas Server dan Dukungan GPU
Dibangun dengan prosesor komputasi kelas server AMD EPYC 7302P (16-core, 32-thread), QAI-h1290FX dirancang untuk menangani inferensi AI, virtualisasi, dan beban kerja paralel yang berat.
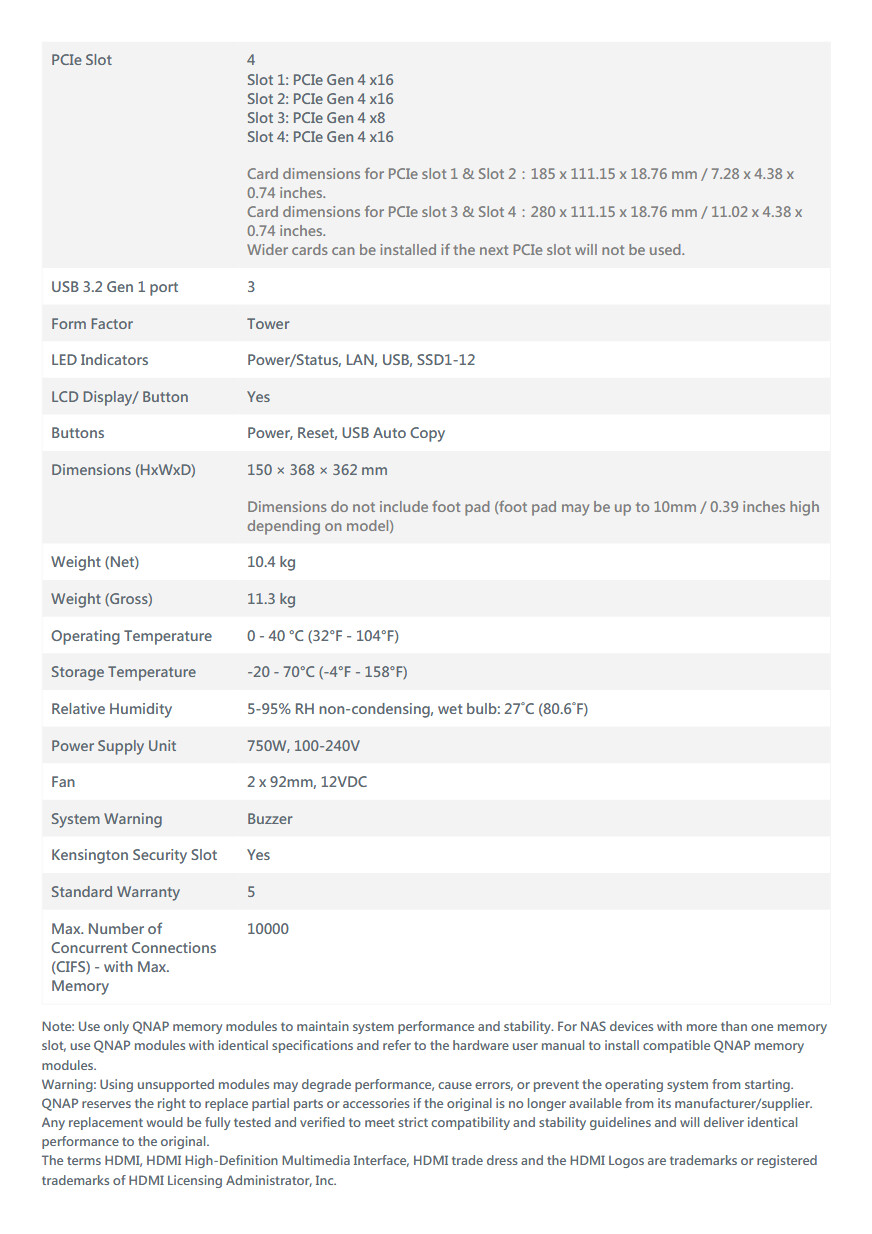
Untuk memastikan kecepatan baca/tulis data yang masif, server ini dilengkapi dengan dua belas slot SSD U.2 NVMe/SATA yang mewujudkan arsitektur penyimpanan all-flash dengan I/O ultra-cepat. Lebih lanjut, server ini siap untuk diintegrasikan dengan akselerasi GPU kelas atas, mendukung opsi GPU Workstation NVIDIA RTX PRO 6000 Blackwell Max-Q dengan memori GPU hingga 96 GB. Kombinasi ini memberikan peningkatan performa yang signifikan untuk inferensi LLM on-premise, pembuatan gambar, dan beban kerja deep learning.
Infrastruktur AI on-premise berkinerja tinggi ini sangat ideal bagi organisasi yang menuntut inferensi latensi rendah, privasi data penuh, dan kontrol operasional mutlak—tanpa harus bergantung pada layanan cloud pihak ketiga.

OS QuTS hero dan Ekosistem AI Siap Pakai
Ditenagai oleh sistem operasi QuTS hero berbasis ZFS milik QNAP, QAI-h1290FX menyediakan integritas data tingkat perusahaan, snapshot yang nyaris tak terbatas, dan deduplikasi sebaris (inline).
Tim TI, pengembang, dan kelompok riset dapat dengan efisien menjalankan model inferensi dan aplikasi AI generatif berkat dukungan akses GPU native dalam kontainer melalui Container Station dan GPU passthrough untuk mesin virtual via Virtualization Station. Manajemen sumber daya GPU dapat dilakukan secara intuitif tanpa memerlukan konfigurasi baris perintah (command-line).
“Kami ingin menghilangkan hambatan dalam membangun workstation GPU, menginstal alat, dan mengonfigurasi lingkungan yang kompleks,” ungkap Oliver Lam, Manajer Produk di QNAP. “Dengan QAI-h1290FX, pengguna dapat langsung menyebarkan dan menjalankan model AI mereka—dengan kendali penuh atas data mereka dan tanpa ketergantungan pada cloud.”
Untuk memfasilitasi hal tersebut, QAI-h1290FX menyertakan pilihan alat AI bawaan (preloaded) yang dikurasi, seperti AnythingLLM, OpenWebUI, dan Ollama, yang memungkinkan penerapan alur kerja LLM pribadi secara cepat. Aplikasi AI tambahan seperti Stable Diffusion, ComfyUI, n8n, dan vLLM juga sedang diintegrasikan untuk memperluas fungsionalitasnya di masa mendatang.
Konektivitas dan Kasus Penggunaan
Untuk mendukung perpindahan data berskala raksasa, server AI ini hadir dengan jaringan berkecepatan tinggi: port ganda 25GbE dan port ganda 2.5GbE, ditambah slot PCIe yang mendukung peningkatan (upgrade) opsional hingga 100GbE.
Dengan QAI-h1290FX, perusahaan dapat langsung mengeksekusi berbagai skenario penggunaan, mulai dari:
- Membangun Asisten AI Internal untuk pencarian pengetahuan karyawan.
- Pencarian Enterprise RAG untuk menyisir dokumen internal dan kontrak secara kontekstual.
- Pembuatan Gambar untuk tim kreatif menggunakan perangkat seperti Stable Diffusion.
- Otomatisasi TI Berbasis AI menggunakan n8n untuk mengotomatiskan tugas inferensi atau peringatan sistem.
Sumber: QNAP