Generasi Selanjutnya HBM Dibidik untuk Mengintegrasikan GPU Core di Dalam Stack Memori
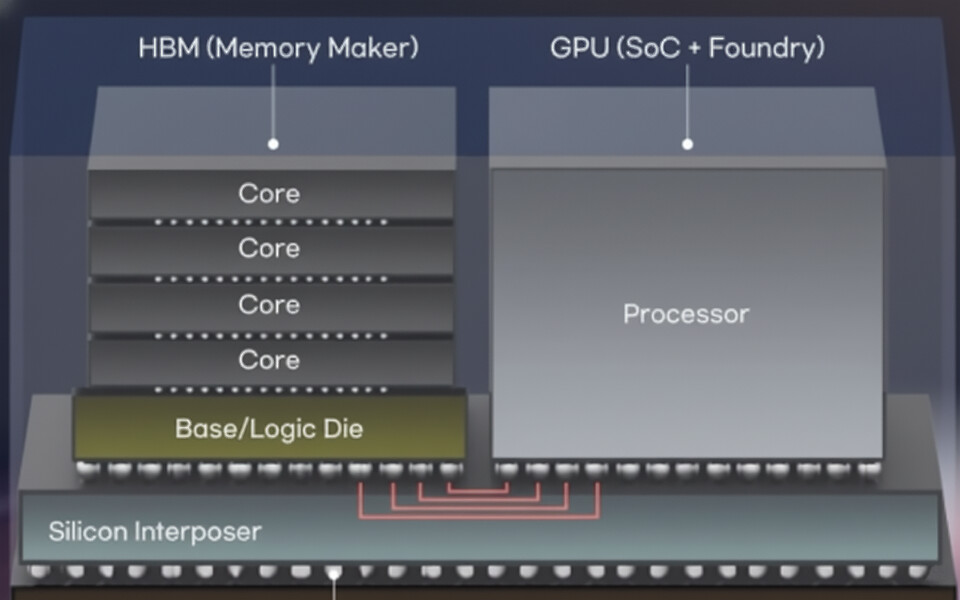
Laporan industri terbaru dari Korea menunjukkan bahwa perusahaan teknologi tengah menjajaki perubahan besar dalam desain HBM (High Bandwidth Memory): integrasi GPU core langsung ke dalam base die stack memori generasi mendatang. Meta dan NVIDIA disebut sedang mengevaluasi konsep “custom HBM” ini, sementara SK Hynix dan Samsung dikabarkan telah terlibat dalam diskusi awal.
Pada prinsipnya, HBM terdiri dari beberapa die DRAM yang ditumpuk di atas sebuah base die yang menangani I/O eksternal. HBM4—diproyeksikan masuk produksi massal tahun depan—akan hadir dengan kontroler terintegrasi untuk meningkatkan efisiensi dan bandwidth. Namun, memasukkan GPU core ke dalam base die adalah langkah yang jauh lebih radikal. Pendekatan ini memindahkan sebagian komputasi langsung ke dalam memori, sehingga dapat mengurangi pergerakan data, menurunkan konsumsi daya, dan meningkatkan performa untuk beban kerja AI.
Sumber industri menyebut bahwa arsitektur semacam ini berpotensi memberikan lompatan besar dalam efisiensi-kinerja dengan mengurangi jarak antara compute dan memori. Namun, sejumlah tantangan besar masih harus diatasi, mulai dari keterbatasan area die dalam stack berbasis TSV, manajemen suplai daya, hingga kesulitan mendinginkan logic GPU yang sangat padat ketika ditempatkan di dalam base die.
Kim Joung-ho, profesor dari KAIST, menilai bahwa kecepatan transisi teknologi akan semakin meningkat seiring kaburnya batas antara memori dan semikonduktor sistem dalam ranah AI. Ia menekankan bahwa perusahaan membutuhkan ekspansi ekosistem melampaui memori menuju sektor logika untuk memimpin pasar HBM generasi berikutnya.
Tren menuju integrasi compute-memory ini juga terlihat dari desain akselerator AI terbaru. AMD Instinct MI430X yang dibangun di atas arsitektur AMD CDNA generasi baru mendukung 432 GB HBM4 dengan bandwidth 19,6 TB/s. Sementara itu, NVIDIA Vera Rubin Superchip menggunakan pendekatan lain: dua chiplet komputasi berskala reticle dipasangkan dengan delapan stack HBM4, menghasilkan sekitar 288 GB HBM4 per GPU dan 576 GB untuk seluruh superchip.
Perubahan besar ini diperkirakan akan menguntungkan perusahaan dengan kemampuan packaging dan logika tingkat tinggi, sementara produsen memori murni mungkin harus memperluas kompetensi ke semikonduktor sistem untuk tetap bersaing di era HBM terintegrasi.
Sumber: ET News








