
Performa inferensi menjadi faktor krusial dalam “pabrik AI”, karena throughput yang tinggi langsung berpengaruh pada kecepatan produksi token, efisiensi biaya, serta produktivitas sistem secara keseluruhan. Kurang dari setengah tahun sejak debutnya di ajang GTC, sistem NVIDIA GB300 NVL72 berbasis arsitektur Blackwell Ultra mencatatkan rekor di benchmark MLPerf Inference v5.1, dengan throughput inferensi DeepSeek-R1 hingga 1,4x lebih tinggi dibanding sistem GB200 NVL72 berbasis Blackwell standar.
Peningkatan Arsitektur Blackwell Ultra
Blackwell Ultra dibangun di atas fondasi Blackwell dengan sejumlah peningkatan signifikan:
- 1,5x lebih banyak NVFP4 AI compute
- 2x akselerasi layer attention
- Hingga 288 GB HBM3e per GPU
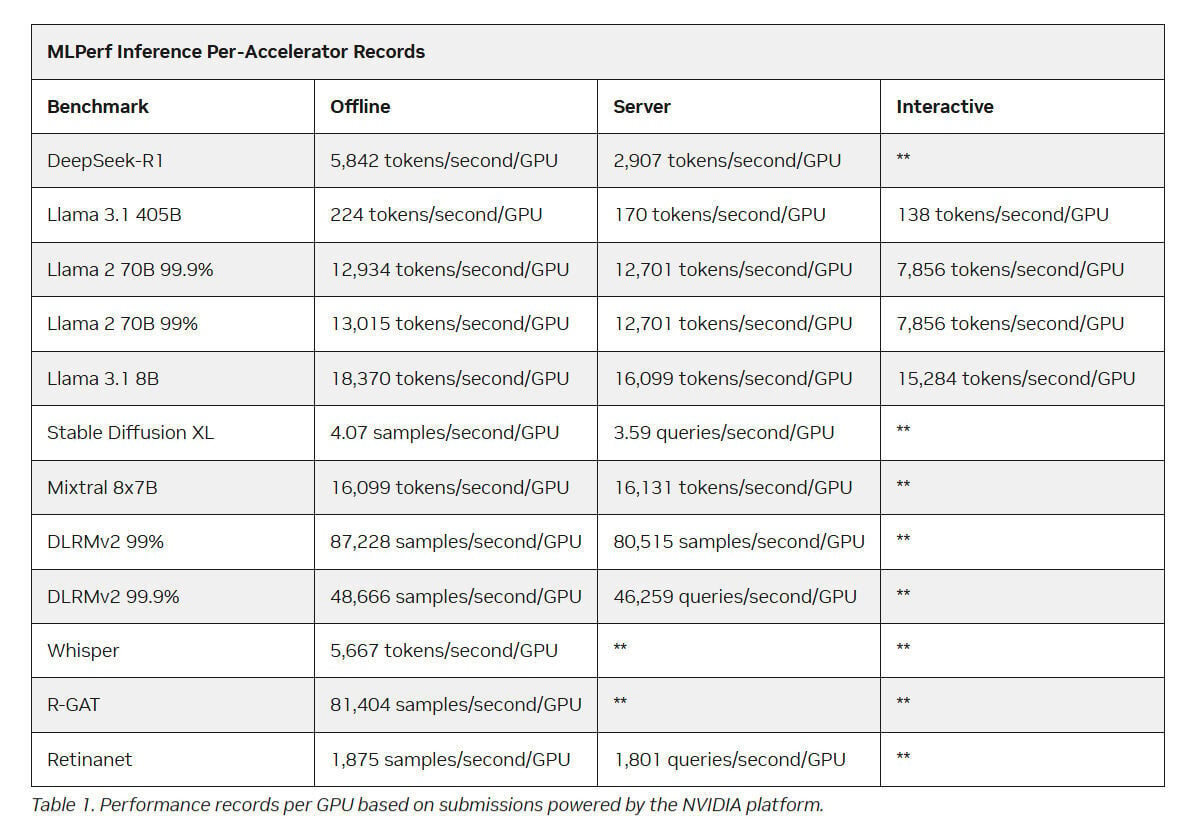
Selain itu, platform ini juga mencetak rekor pada semua benchmark data center baru di MLPerf v5.1, termasuk DeepSeek-R1, Llama 3.1 405B Interactive, Llama 3.1 8B, dan Whisper, sekaligus mempertahankan rekor per-GPU di setiap benchmark data center MLPerf.
Full-Stack Optimization
Keberhasilan ini tidak lepas dari pendekatan full-stack co-design. Arsitektur Blackwell dan Blackwell Ultra menyertakan akselerasi perangkat keras untuk format data NVFP4—format floating point 4-bit rancangan NVIDIA yang menawarkan akurasi lebih tinggi dibanding FP4 lainnya, dengan presisi sebanding format lebih tinggi.
Dengan kombinasi NVIDIA TensorRT Model Optimizer dan pustaka TensorRT-LLM, model seperti DeepSeek-R1, Llama 3.1 405B, Llama 2 70B, hingga Llama 3.1 8B berhasil dioptimalkan ke NVFP4, menghasilkan performa lebih tinggi tanpa mengorbankan akurasi.
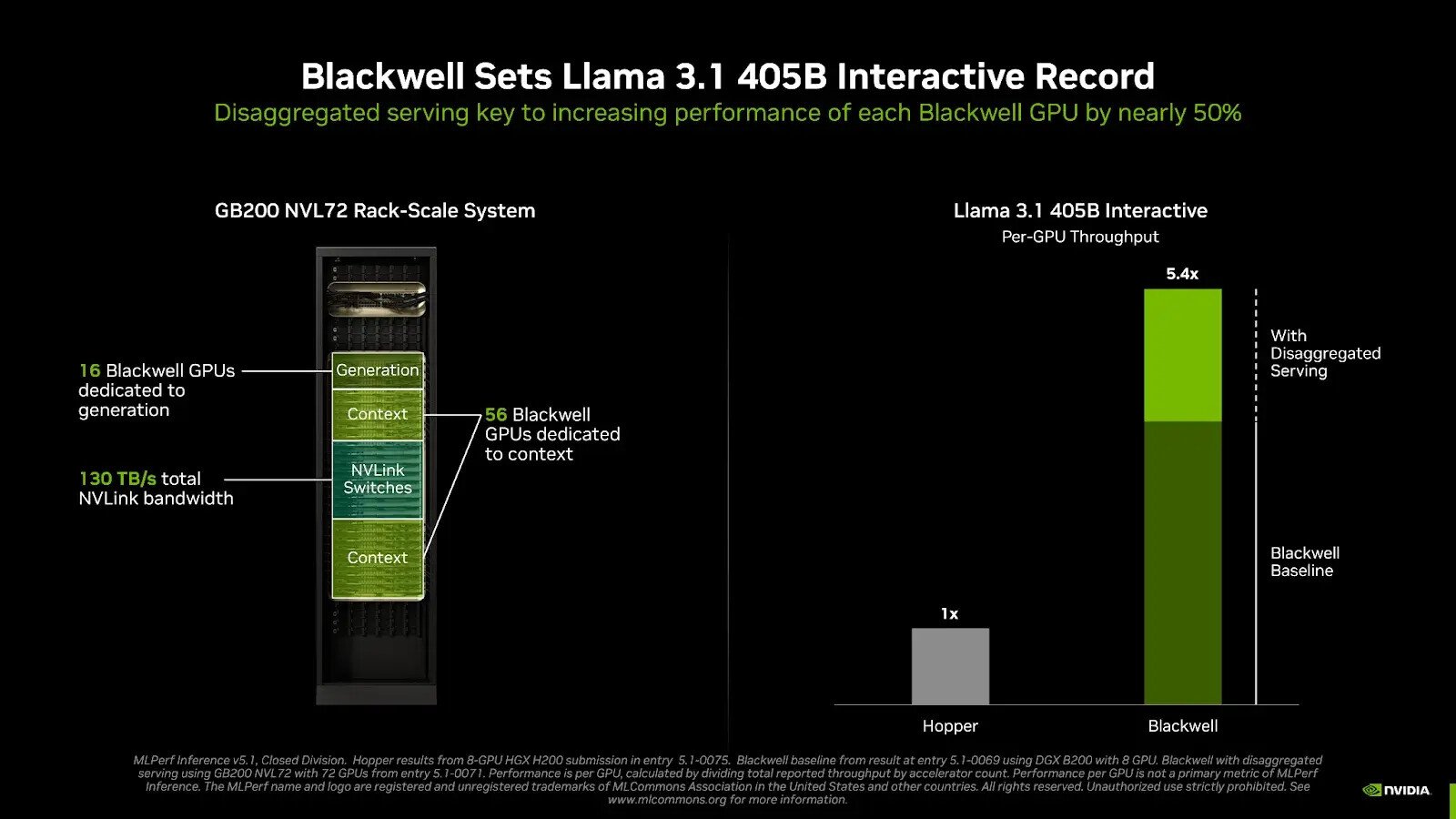
Teknik Disaggregated Serving
Inferensi LLM terdiri atas dua fase: pemrosesan konteks untuk menghasilkan token pertama, dan fase generasi untuk token berikutnya. Teknik disaggregated serving memisahkan kedua fase ini sehingga bisa dioptimalkan secara independen. Pendekatan ini terbukti mampu meningkatkan performa hampir 50% per GPU pada benchmark Llama 3.1 405B Interactive, dibanding metode tradisional di server DGX B200.
Ekosistem dan Dukungan Mitra
NVIDIA juga untuk pertama kalinya menyertakan framework inferensi NVIDIA Dynamo dalam pengiriman benchmark. Sejumlah mitra besar ikut serta menunjukkan hasil dengan platform Blackwell maupun Hopper, termasuk Azure, Dell Technologies, Cisco, HPE, Lenovo, Oracle, Supermicro, hingga University of Florida.
Dengan performa inferensi terdepan, platform AI NVIDIA kini tersedia luas melalui penyedia cloud dan server global. Hal ini memberikan keuntungan berupa TCO lebih rendah dan ROI lebih tinggi bagi organisasi yang mengimplementasikan aplikasi AI berskala besar.
Sumber: NVIDIA








