

Cloudflare mengonfirmasi gangguan besar pada jaringan globalnya pada 18 November 2025 yang menyebabkan kegagalan pengantaran lalu lintas inti dan memunculkan halaman error (HTTP 5xx) di situs-situs yang mengandalkan layanan perusahaan. Perusahaan menyatakan insiden ini bukan akibat serangan siber, melainkan kelalaian konfigurasi yang memicu rantai kegagalan pada modul Bot Management.
Kesalahan konfigurasi memicu kegagalan
Menurut penjelasan resmi Cloudflare, masalah bermula dari perubahan hak akses pada satu sistem basis data ClickHouse. Perubahan itu membuat kueri yang menghasilkan berkas konfigurasi fitur (feature file) untuk sistem Bot Management mulai mengembalikan baris duplikat—akibatnya ukuran berkas lebih dari dua kali lipat dari yang diharapkan. Berkas konfigurasi yang membengkak itu lalu didistribusikan ke seluruh mesin jaringan Cloudflare.
Perangkat lunak proxy inti yang membaca berkas fitur tersebut memiliki batasan jumlah fitur yang sudah dipraalokasi (200 fitur). Ketika berkas baru melebihi batas ini, modul Bot Management mengalami panic dan membuat proxy inti gagal menangani permintaan, sehingga menghasilkan gelombang error 5xx yang meluas.
Fluktuasi kegagalan mempersulit penanganan
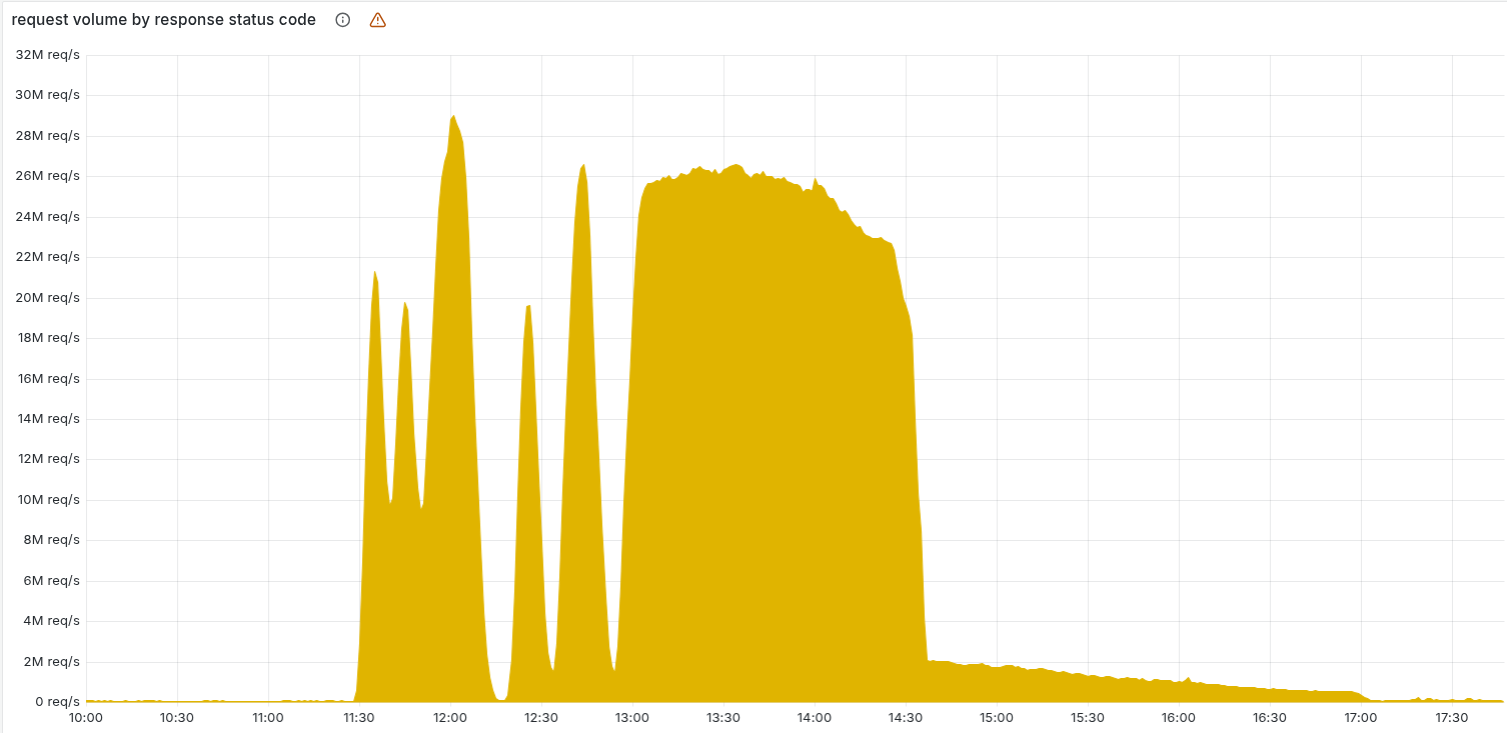
Siklus pembuatan berkas keliru oleh beberapa node ClickHouse setiap lima menit menyebabkan kondisi sistem berganti-ganti antara status sehat dan gagal. Fluktuasi ini awalnya menimbulkan kebingungan tim teknis dan sempat membuat mereka menduga serangan DDoS sebagai penyebab. Hanya setelah semua node ClickHouse menghasilkan berkas yang salah, kondisi stabil dalam keadaan gagal dan penyebab sebenarnya diidentifikasi.
Layanan terdampak dan mitigasi sementara
Gangguan berdampak pada sejumlah layanan Cloudflare, antara lain CDN inti, sistem otentikasi Access, Workers KV, Turnstile, dan Dashboard. Beberapa efek yang dicatat meliputi:
- Lalu lintas web mengalami peningkatan latensi dan banyak permintaan yang dibalas dengan kode error 5xx.
- Turnstile gagal memuat sehingga banyak pengguna tidak dapat masuk ke Dashboard jika mereka belum memiliki sesi aktif.
- Workers KV mengalami kegagalan karena bergantung pada proxy inti; tim mengimplementasikan bypass untuk mengurangi dampak.
- Konfigurasi Access tidak terproses dengan benar sampai mitigasi diberlakukan, menyebabkan kegagalan otentikasi bagi sebagian pengguna.
Tim teknis menghentikan proses pembuatan dan distribusi berkas fitur yang salah pada 14:24 UTC, menggantinya dengan versi berkas terakhir yang diketahui baik, lalu me-restart proxy inti. Perbaikan utama selesai sekitar 14:30 UTC dan pada 17:06 UTC semua layanan dilaporkan pulih sepenuhnya.
Akar teknis: perubahan perilaku kueri ClickHouse
Perubahan yang dikerjakan tim untuk memperhalus kontrol hak akses agar kueri terdistribusi berjalan di bawah akun pengguna awal menyebabkan metadata tabel ClickHouse kini mengekspos tabel dasar (r0). Kueri metadata yang tidak memfilter nama basis data mulai mengembalikan entri ganda—kolom untuk tabel di default dan juga untuk tabel di r0—yang menggandakan jumlah fitur yang dimasukkan ke berkas output.
Karena implementasi modul proxy melakukan pra-alokasi memori berdasarkan jumlah fitur yang diperkirakan, lonjakan fitur ini menimbulkan kondisi out-of-bounds yang tidak tertangani oleh kode Rust di FL2, memicu panic dan kegagalan layanan.
Pelajaran dan langkah pencegahan
Cloudflare menyebut insiden ini sebagai salah satu outage terburuk sejak 2019 dan mengumumkan serangkaian tindakan untuk mencegah kejadian serupa di masa depan, termasuk:
- Menguatkan validasi dan sanitasi berkas-berkas konfigurasi yang dihasilkan secara internal, sama ketatnya seperti terhadap input pengguna.
- Menyediakan kill switch global untuk fitur yang bermasalah sehingga distribusi konfigurasi dapat diputus dengan cepat.
- Mencegah core dump atau laporan kesalahan lainnya memenuhi sumber daya sistem.
- Meninjau ulang mode kegagalan pada tiap modul proxy agar error lebih terkendali dan tidak menyebar ke layanan lain.
Cloudflare juga mengakui bahwa keterbatasan observabilitas dan asumsi lama mengenai bentuk data metadata berkontribusi pada kegagalan ini, dan berjanji memperbaiki proses rollout serta kontrol perubahan untuk mengurangi risiko regresi saat melakukan pembaruan infrastruktur.
Kronologi singkat
- 11:05 UTC — Perubahan hak akses ClickHouse mulai digulirkan.
- 11:28 UTC — Dampak mulai muncul pada lalu lintas pelanggan.
- 13:05 UTC — Bypass Workers KV dan Access diterapkan untuk mengurangi dampak.
- 14:24–14:30 UTC — Distribusi berkas yang salah dihentikan; berkas lama dikembalikan; recovery utama dimulai.
- 17:06 UTC — Semua layanan diperkirakan pulih.
Insiden ini menegaskan bahwa komponen konfigurasi terdistribusi yang sering diperbarui—seperti yang digunakan untuk model machine learning deteksi bot—memerlukan kontrol ketat terhadap ukuran, validitas, dan skenario kegagalan. Bagi operator layanan dan arsitek jaringan, kejadian Cloudflare adalah pengingat penting tentang risiko pra-alokasi memori, asumsi metadata, dan kebutuhan untuk kill switch operasional pada perubahan konfigurasi global.