

Diterjemahkan & disusun oleh Ahmandonk.com berdasarkan TechPowerUp, dengan penyusunan ulang dan penyesuaian konteks teknis untuk pembaca Indonesia. Artikel teknis mendalam mengenai arsitektur Intel Panther Lake: proses 18A, packaging Foveros-S, CPU Cougar Cove & Darkmont, fabric generasi kedua, GPU Xe3 “Celestial”, konektivitas, akselerator AI/Media, dan klaim performa.
Introduction
Intel baru saja menggelar acara Tech Tour 2025 di Arizona, lokasi dari pabrik barunya yang menggunakan proses Intel 18A. Dalam kunjungan eksklusif ini, kami berkesempatan melihat langsung bagaimana Intel merancang platform mobile generasi mendatang mereka — Panther Lake. Selain presentasi resmi (materi lengkap berada di bagian akhir sesi), kami juga memperoleh akses on/off the record dengan para insinyur dan eksekutif kunci. Dari situ, kami bisa merangkai keterkaitan teknologi proses, packaging, dan arsitektur ke dalam sebuah narasi yang utuh.
Meski 18A menjadi fondasi, Panther Lake bukan sekadar node baru. Intel memperkenalkan RibbonFET dan PowerVia dalam arsitektur hybrid yang memadukan Cougar Cove P-cores, Darkmont E-cores, dan low-power cores, dikelola oleh Thread Director yang lebih cerdas. Next-gen fabric yang lebih cepat menghubungkan CPU, GPU, NPU, dan IPU agar data mengalir mulus. Di sisi grafis, arsitektur Xe3 “Celestial” menghadirkan lompatan performa, multi-frame generation, serta integrasi erat dengan NPU/IPU untuk tugas AI & media. Dikombinasikan dengan Foveros-S, Wi-Fi 7, dan kontrol daya yang ditingkatkan, Panther Lake menjanjikan performa lebih tinggi, efisiensi lebih baik, dan responsivitas lebih cepat di berbagai beban kerja.
Artikel ini menelusuri proses & packaging, tumpukan produk dan konfigurasi tile, perubahan CPU & cache, fabric terbaru, scheduling & power, grafis Xe3, konektivitas, hingga mesin AI/media — sekaligus merangkum klaim performa dan timeline untuk menyiapkan ekspektasi jelang peluncuran.
⏩ Halaman Selanjutnya: Inovasi Proses dan Teknologi Packaging
Inovasi Proses dan Teknologi Packaging
Intel 18A adalah proses produksi paling maju yang berhasil dibawa Intel ke skala massal. Kelas fitur “1,8 nm” berarti struktur transistor dan interkoneksi lebih kecil dan rapat, menaikkan kepadatan transistor dan menurunkan energi switching. Untuk chip notebook seperti Panther Lake, hasilnya adalah efisiensi daya lebih baik tanpa peningkatan panas atau konsumsi baterai yang terasa. Intel mengindikasikan gate length sekitar 5–10% lebih pendek saat pindah dari FinFET ke RibbonFET di 18A, dengan pengurangan daya per transistor >20%.
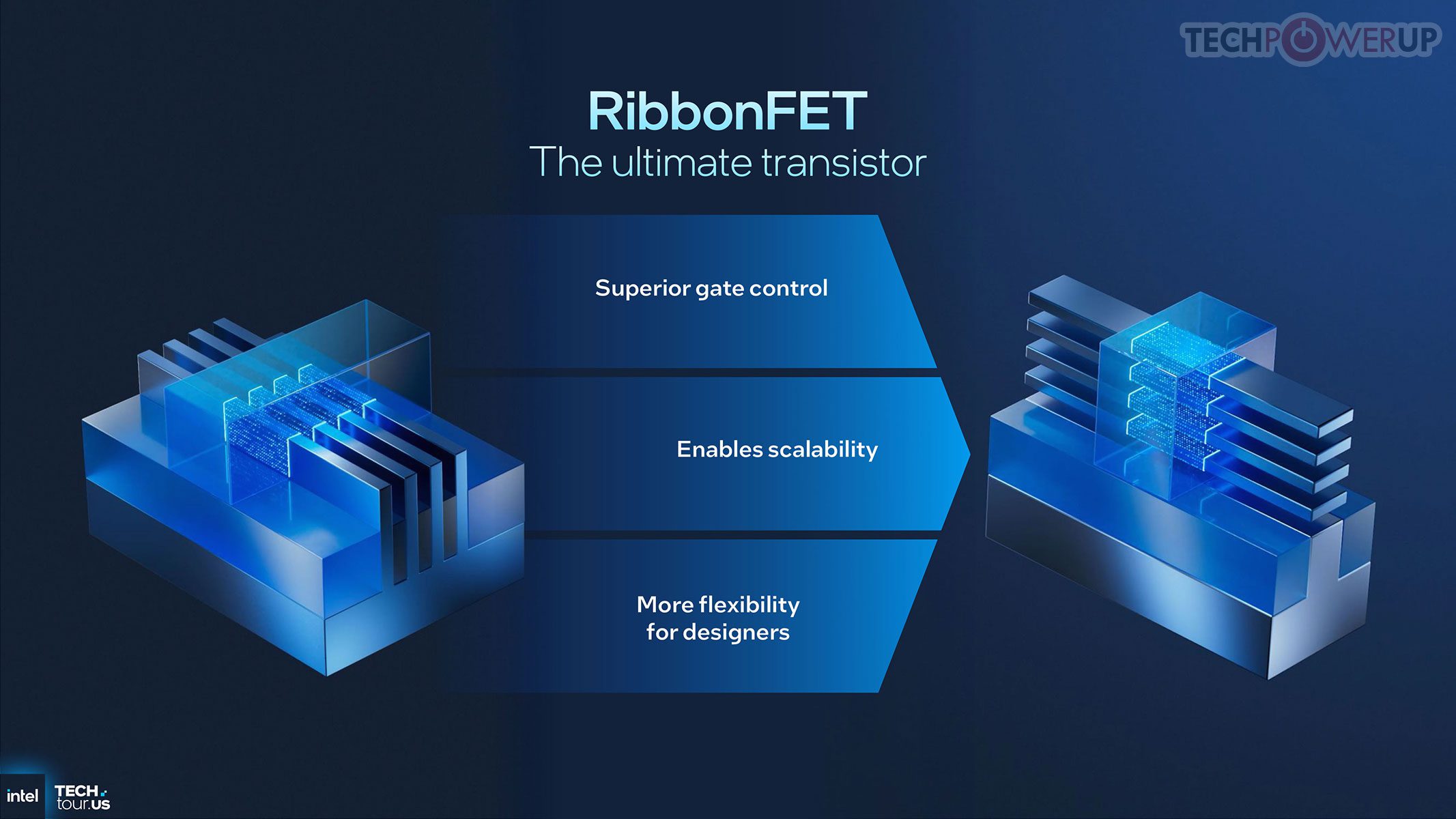
RibbonFET adalah implementasi Gate-All-Around dari Intel: alih-alih sirip vertikal (FinFET), beberapa pita silikon horizontal diselimuti gate di semua sisi. Geometri ini meningkatkan kontrol listrik, menurunkan tegangan operasi, mengurangi leakage, dan meningkatkan efisiensi switching. Dipadukan material yang ditingkatkan dan gate lebih pendek, performa tinggi dapat dipertahankan dengan daya lebih hemat.
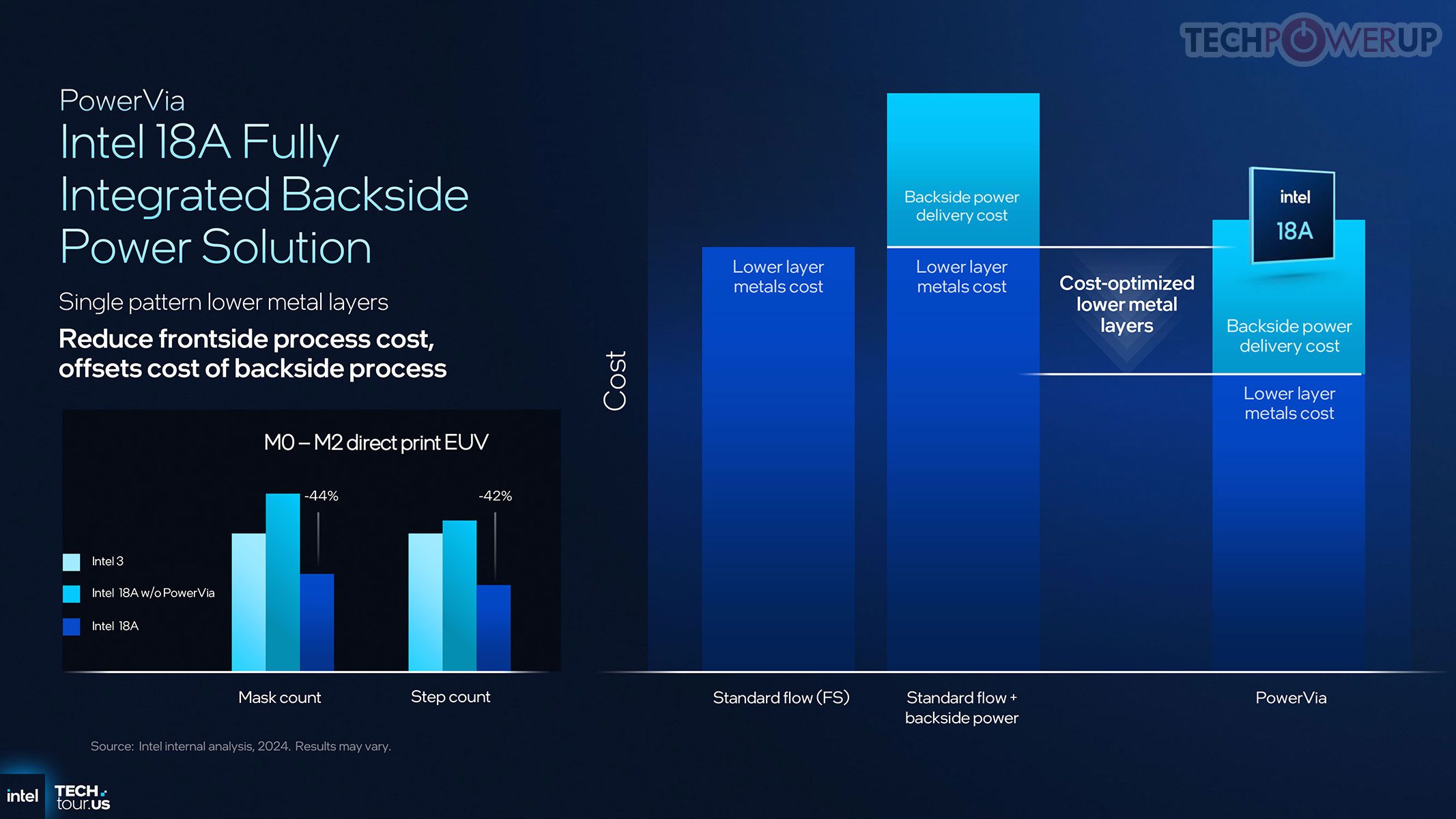
Perubahan besar kedua adalah PowerVia, backside power delivery yang memindahkan jaringan daya ke sisi belakang wafer. Ini membebaskan lapisan atas untuk sinyal data, memendekkan jalur daya, menurunkan resistansi, dan menstabilkan tegangan pada frekuensi tinggi — melengkapi RibbonFET: yang satu fokus kendali transistor, yang lain memastikan suplai daya bersih.
Di level perakitan, Foveros menggabungkan beberapa die/tile menjadi satu produk, baik secara 3D maupun 2.5D. Pendekatan modular ini meningkatkan yield dan memungkinkan tiap tile memakai node proses paling sesuai. Panther Lake menggunakan Foveros-S (2.5D) dengan fine-pitch 36 μm, menghubungkan tile compute (Intel 18A), GPU 12-Xe (TSMC N3E), GPU 4-Xe (Intel 3), dan PCH/PCT (TSMC N6). Fleksibilitas lintas-node ini selaras dengan strategi IDM 2.0 untuk menyeimbangkan target waktu, yield, dan performa.
Kombinasi transistor lebih kecil, backside power yang bersih, dan packaging modular membentuk fondasi Panther Lake — bagian dari pergeseran industri menuju SoC terdisagregasi yang lebih efisien dan mudah diadaptasi, ketimbang die monolitik besar yang mahal dan rentan cacat produksi.






⏩ Halaman Selanjutnya: Posisi Panther Lake di Lini Produk Intel
Posisi Panther Lake di Lini Produk Intel
Roadmap Intel menggambarkan perjalanan dari Meteor Lake (SoC disaggregated pertama) ke Lunar Lake (daya rendah + memori terintegrasi) dan Arrow Lake (fokus performa), menuju Panther Lake yang memadukan core efisiensi dan performa dalam satu desain yang dapat diskalakan lintas segmen notebook.
Panther Lake adalah prosesor pertama Intel yang memakai Intel 18A untuk compute tile; GPU tile memakai Intel 3 atau TSMC N3E, sementara tile lain (seperti PCT) diproduksi TSMC. Ini menandai strategi pasokan hibrida: Intel Foundry Services fokus pada core logic, sedangkan beberapa tile lain dari mitra eksternal — meningkatkan fleksibilitas kapasitas dan waktu.
Panther Lake hadir dalam tiga konfigurasi, masing-masing terdiri dari compute, GPU, dan platform controller tile yang terhubung melalui Scalable Fabric generasi kedua. Secara posisi, ia berada di tengah antara Lunar dan Arrow Lake: membawa efisiensi Lunar ke sistem berperforma lebih tinggi, dan tumpang tindih dengan Arrow Lake di kelas mainstream. Intel membingkai Panther Lake sebagai arsitektur penyatu portofolio mobile dengan tiga prinsip: perf/W lebih baik, skala kinerja CPU/GPU di rentang daya luas, dan konfigurabilitas tinggi. Tidak ada varian desktop yang disebutkan — fokusnya mobile.







⏩ Halaman Selanjutnya: Konfigurasi Panther Lake
Konfigurasi Panther Lake
SoC Panther Lake terdiri dari tiga tile: compute (Intel 18A), graphics (Intel 3 untuk 4-Xe dan TSMC N3E untuk 12-Xe), dan platform controller (TSMC N6). Ketiganya digandeng oleh Scalable Fabric Gen-2 agar bertindak sebagai satu sistem koheren meski beda node proses.
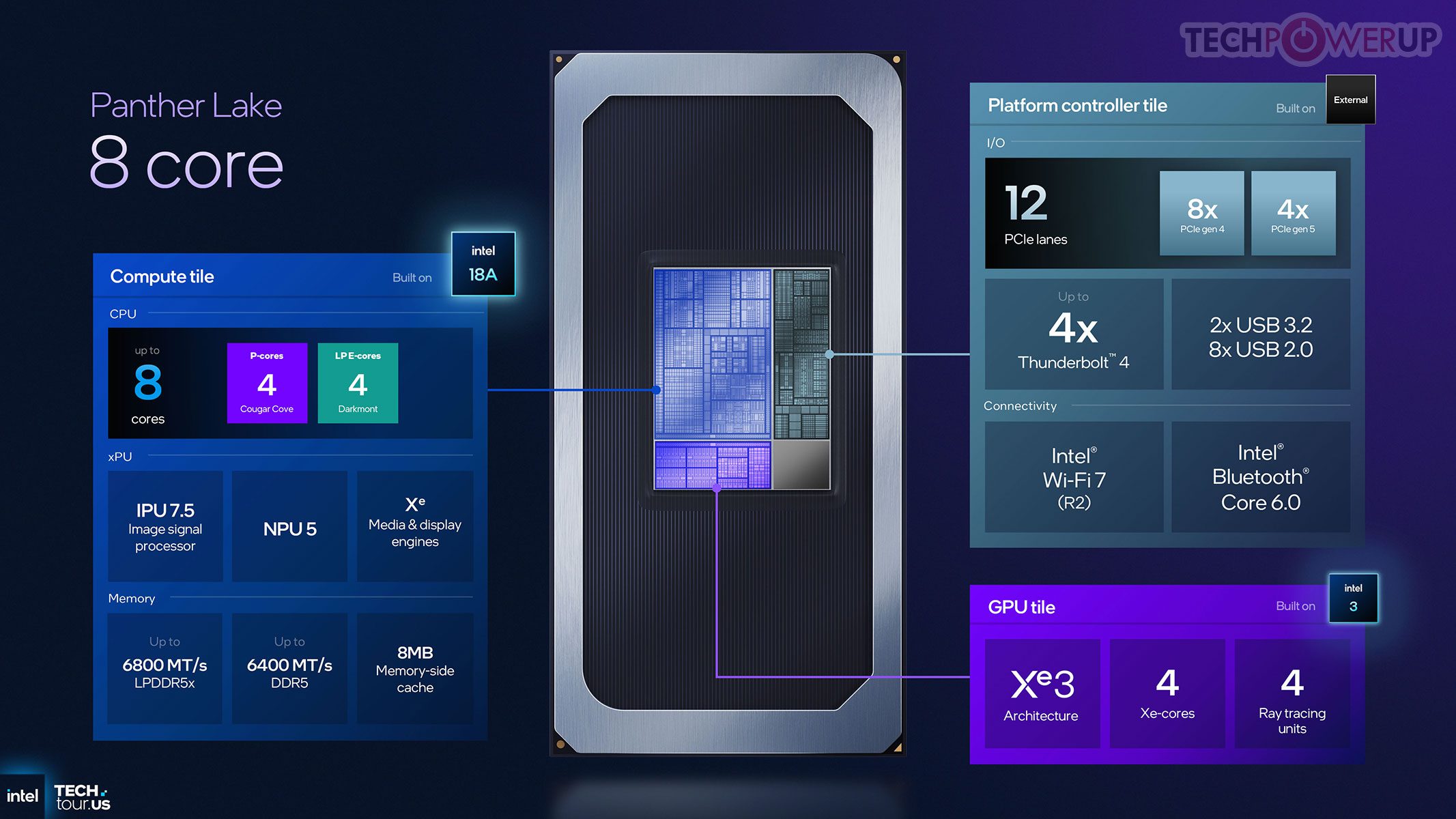
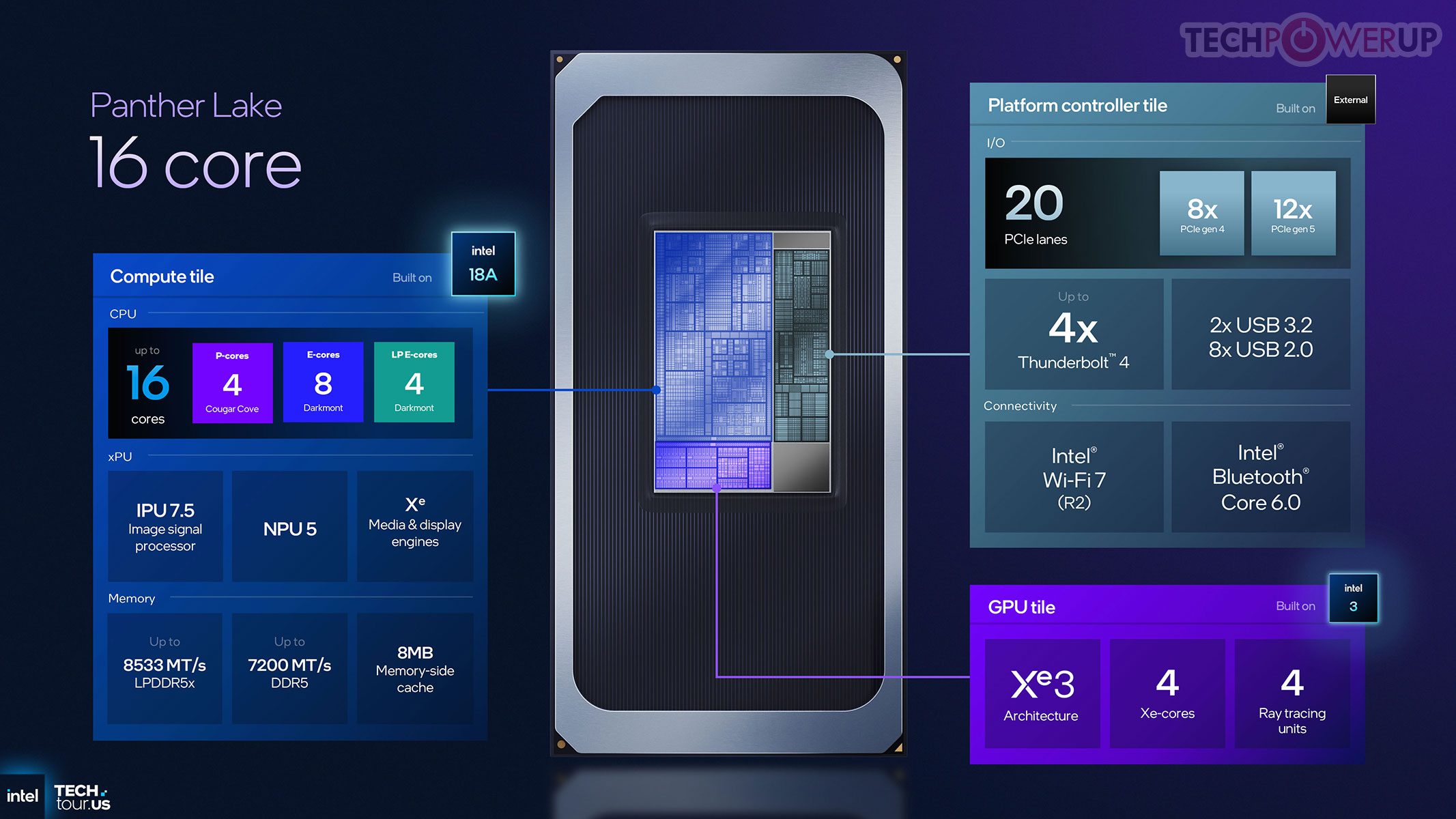
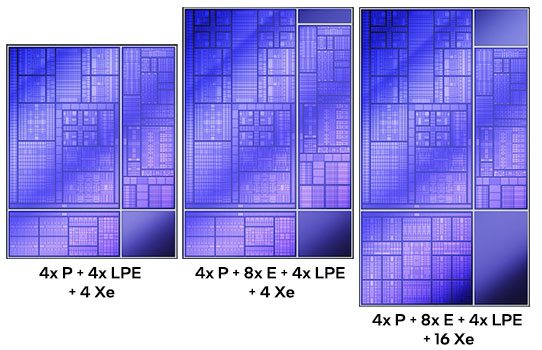
Compute tile memadukan 4 P-Core Cougar Cove, 8 E-Core Darkmont pada die 4+8+4, dan 4 LP-E Core, semuanya terhubung ring bus terpadu untuk berbagi cache/memori berlatensi rendah. Tiga paket utama: (1) 4P + 4 LP-E + GPU 4-Xe, (2) 4P + 8E + 4 LP-E + GPU 4-Xe, dan (3) 4P + 8E + 4 LP-E + GPU 12-Xe (flagship). Beberapa paket memakai dummy die non-fungsi untuk stabilitas mekanis.
Setiap Xe core membawa vector & matrix engine yang diperbarui, cache lebih besar, dan unit ray tracing yang ditingkatkan. PCT dari TSMC mengintegrasikan IMC, PCIe Gen 5, Thunderbolt, dan konektivitas nirkabel CNVio; mendukung LPDDR5x (disolder) dan DDR5 (socket). Modularitas tile memungkinkan skala dari ultra-low power hingga high-performance notebook.











⏩ Halaman Selanjutnya: Desain Inti Cougar Cove & Darkmont
Desain Inti Cougar Cove & Darkmont
Cougar Cove (P-Core) meneruskan Lion Cove dengan fokus efisiensi dan konsistensi. Front-end dirombak agar aliran instruksi stabil; scheduler menyalurkan kerja dengan lebih sedikit stall. Struktur internal (dispatch/allocation queue) sedikit diperlebar untuk menyeimbangkan throughput vs energi, menghasilkan +5–10% perf/clock pada frekuensi sama. Cache: L1 256 KB per core dan L2 3 MB private per core. Pipeline depth tetap, tetapi branch predictor, instruction fusion, dan prefetch disempurnakan; reorder buffer dan allocation windows diatur ulang untuk menyeimbangkan integer/vektor, mengurangi wasted wakeups dan meningkatkan efisiensi steady-state.
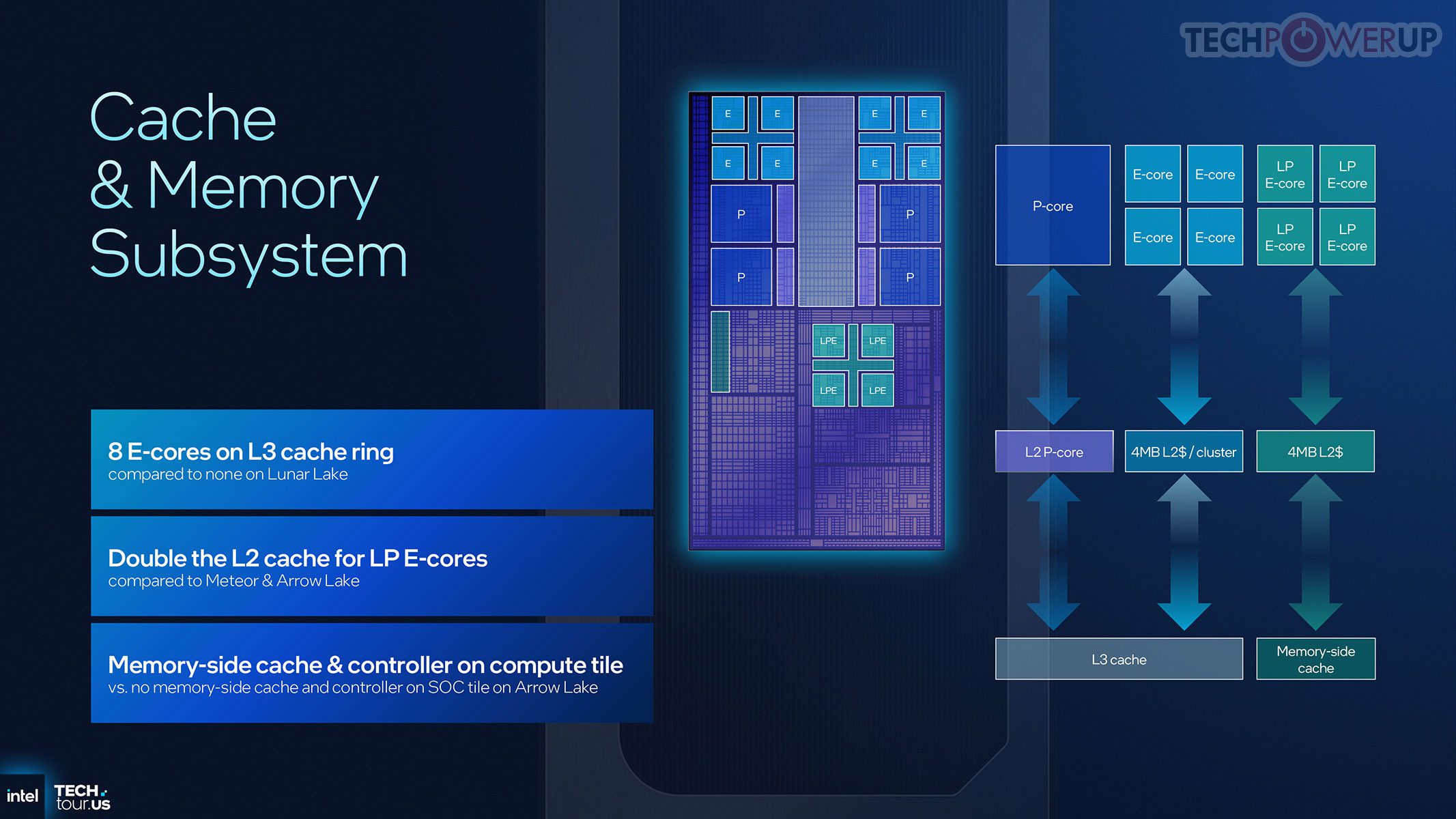
Darkmont (E-Core) menggantikan Crestmont dengan lompatan arsitektur: pipeline lebih lebar, jendela out-of-order lebih besar, unit vektor lebih cepat, latensi memori lebih rendah, dan eksekusi spekulatif lebih agresif. Tujuannya memperkecil jarak performa ke P-Core sehingga lebih banyak beban bisa tetap di cluster efisien tanpa kehilangan responsivitas. Cache Darkmont: L1 96 KB per core dan L2 4 MB per cluster.
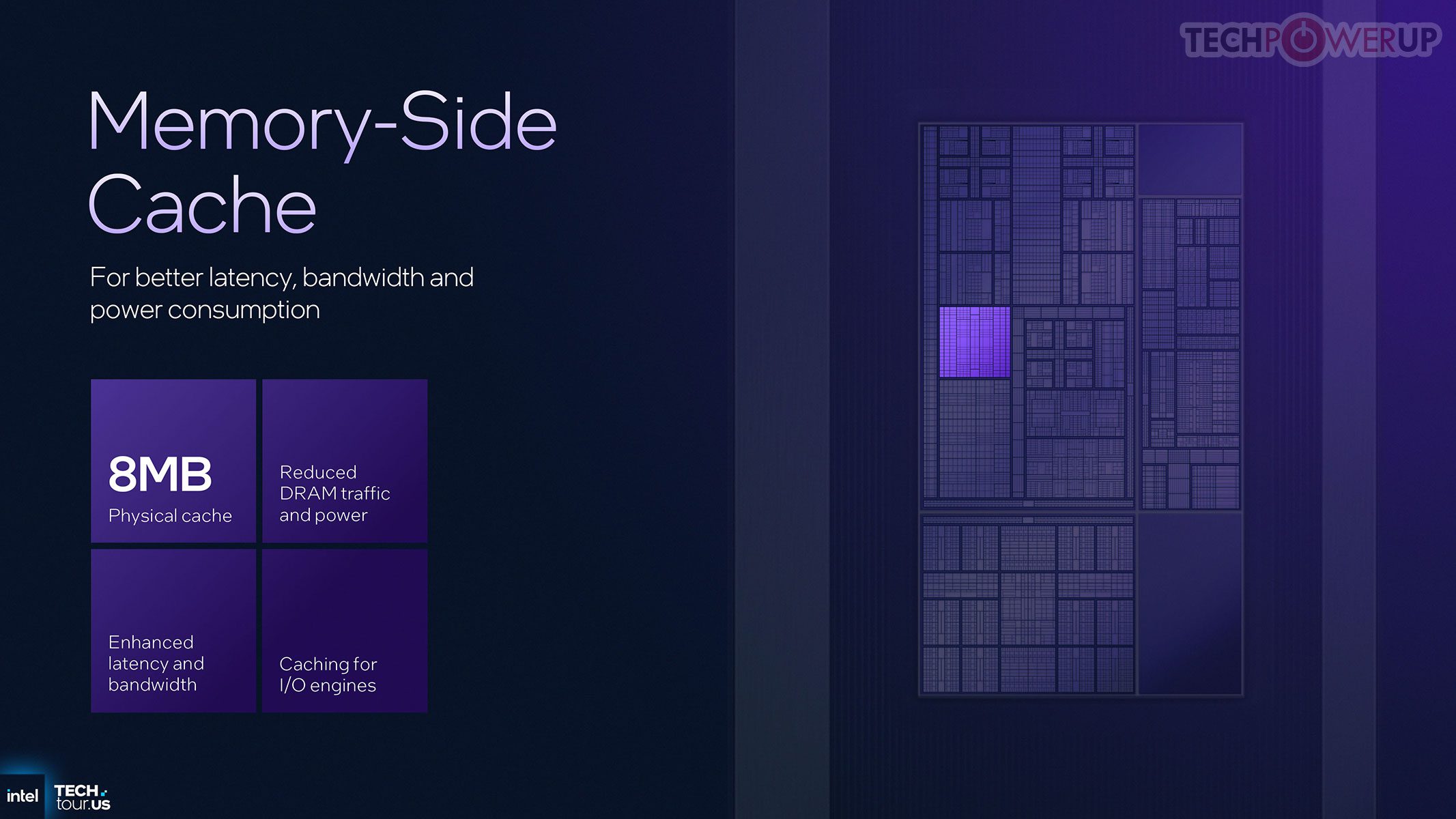
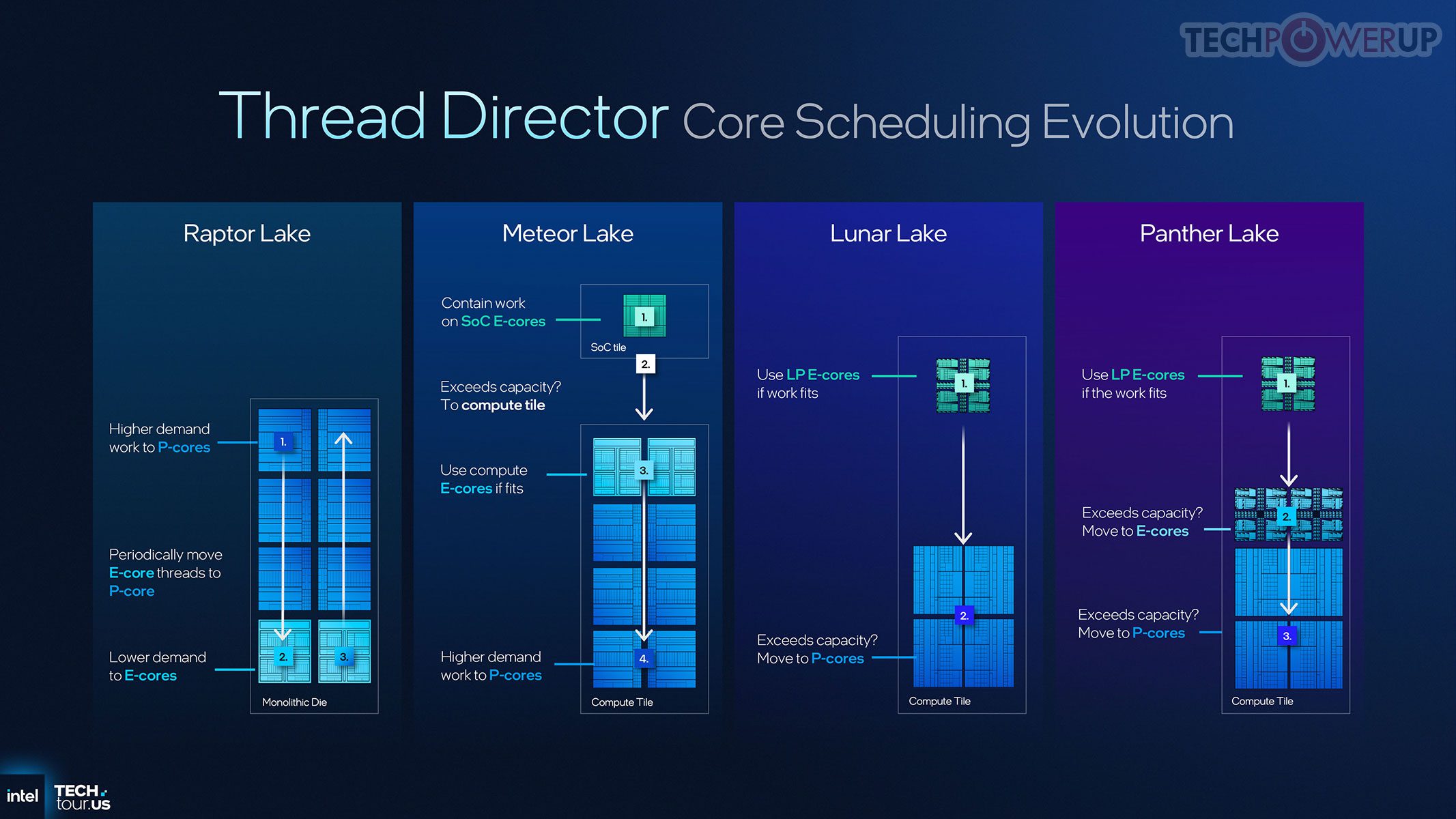
Thread Director dituning untuk kombinasi Cougar Cove, Darkmont, dan LP-E: memberi feedback granular ke OS soal kebutuhan latensi dan penggunaan cache tiap thread, sehingga penempatan tugas lebih tepat untuk responsivitas dan efisiensi. Fitur baru di compute tile adalah Memory-Side Cache 8 MB yang dapat diakses semua blok utama (bukan hanya CPU), berfungsi sebagai buffer cepat bersama untuk mengurangi lalu-lintas ke memori sistem — misalnya IPU saat memproses video webcam.
Secara keseluruhan, compute tile memberikan perf/W lebih tinggi dari Lunar Lake pada frekuensi mirip, berkat transistor 18A, PowerVia, dan penyempurnaan mikroarsitektur.









⏩ Halaman Selanjutnya: Peningkatan Cache & Fabric
Peningkatan Cache & Fabric
Scalable Fabric generasi kedua menyatukan compute, graphics, dan platform controller tile menjadi satu sistem koheren: bandwidth naik, latensi turun, dan biaya daya perpindahan data lebih rendah. Unified memory fabric memberi ruang alamat tunggal bagi CPU, GPU, IPU, dan NPU — akses data bersama tanpa penyalinan eksplisit atau buffer sinkronisasi terpisah.
Hierarki cache didesain ulang untuk mengurangi kontensi dan mendukung mixed workloads. L3 bersama di compute tile memiliki asosiasi lebih tinggi, jalur akses internal lebih cepat, dan terhubung langsung ke Memory-Side Cache 8 MB. Intel mengonfirmasi GPU tile dapat melakukan snoop ke L3 compute, sehingga berbagi data CPU-GPU lebih cepat dan hemat daya.
Mekanisme koherensi baru berbasis direktori memprediksi cache slice yang relevan, menghindari broadcast ke semua cluster — mengurangi trafik interkoneksi dan konsumsi daya dengan sinkronisasi tetap cepat. Tile-to-tile links melalui koneksi pendek/padat di base die Foveros menghadirkan latensi mendekati on-die, memungkinkan beban kerja terakselerasi (encoding video, komputasi GPU, AI) memakai struktur data bersama tanpa salin memori terpisah.





⏩ Halaman Selanjutnya: Scheduling & Manajemen Daya
Scheduling & Manajemen Daya
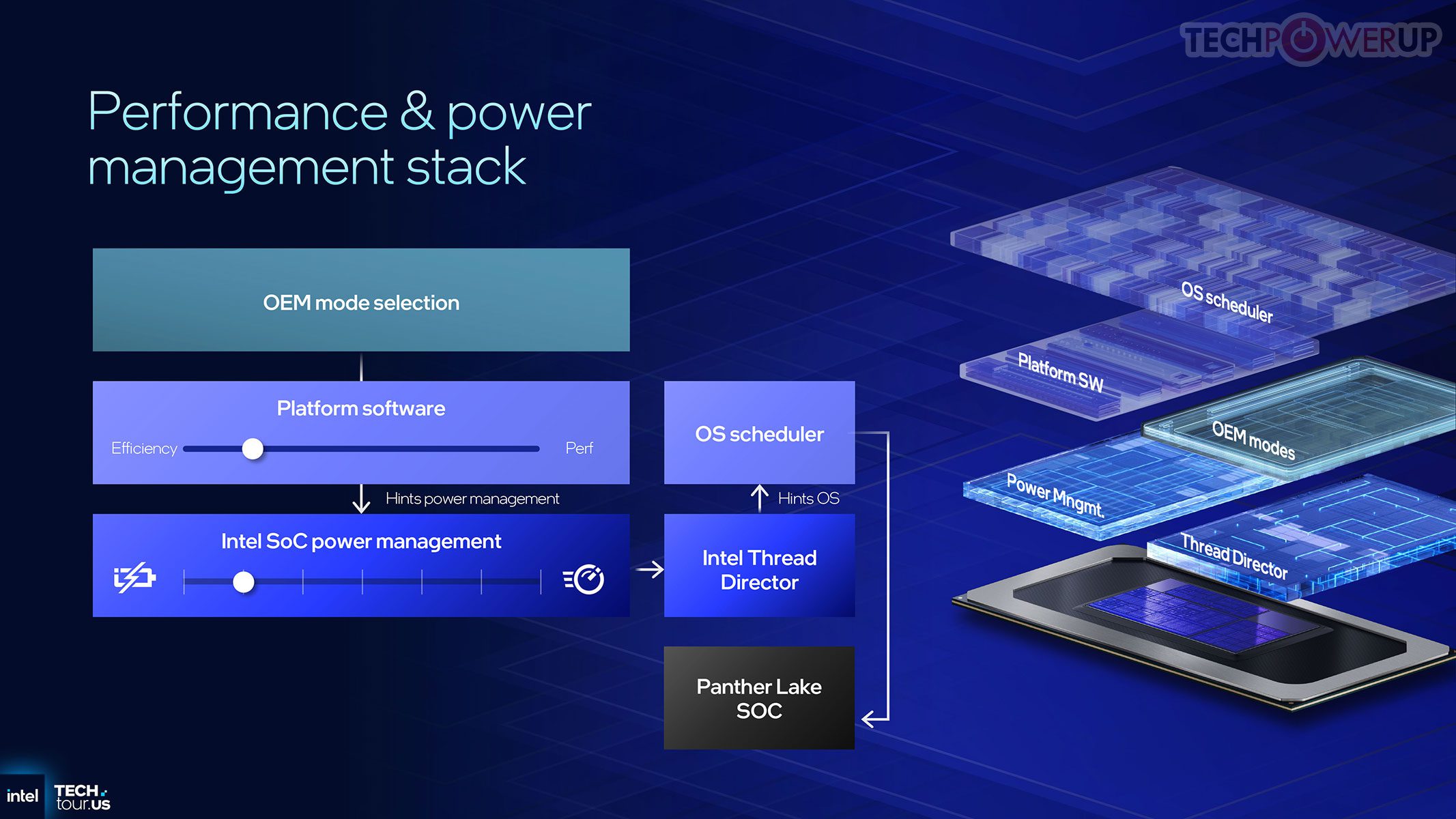
Kerangka daya dan penjadwalan Panther Lake didesain ulang untuk arsitektur hybrid. Thread Director (via ACPI CPPC2 HFI) memonitor instruction mix & aktivitas tiap core, melaporkan ke SoC controller yang mengurutkan core berdasar performa & efisiensi aktual, lalu mengekspos lewat tabel HFI ke OS. Perubahan batas daya/suhu memicu pembaruan tabel dan interrupt; pertukaran data terjadi dalam puluhan mikrodetik, dan OS biasanya mengambil keputusan baru dalam beberapa milidetik — cukup cepat untuk mencegah lag namun stabil agar tidak terjadi migrasi tugas berlebihan.
Manajemen daya berlangsung multilapis: tiap tile bisa masuk low-power sendiri; compute tile bisa power-gate cluster inti; PowerVia meningkatkan stabilitas tegangan saat transisi, memungkinkan fine-grained frequency scaling tanpa jeda. SoC controller pusat mensinkronkan perubahan agar boost GPU/NPU tidak mengganggu komponen lain. Daya dibagi dinamis: saat GPU/NPU berat, frekuensi CPU sedikit diturunkan untuk menjaga power budget, dan sebaliknya.
Firmware menyertakan predictive control loop yang memperkirakan kebutuhan daya beberapa milidetik ke depan dan mengatur voltase/frekuensi lebih awal, dilengkapi fast feedback loop berbasis sensor lintas tile untuk koreksi real time — transisi performa jadi halus, efisien, dan minim lonjakan. 4 LP-E cores menangani beban ringan/selalu-aktif (audio, notifikasi, layanan latar), tetap hidup saat cluster utama idle, mengurangi wakeups, meningkatkan respons, dan memperpanjang baterai.




⏩ Halaman Selanjutnya: GPU Baru: Xe3 “Celestial”
GPU Baru: Xe3 “Celestial”
Arsitektur Xe3 menggantikan Xe2 (Lunar Lake) dan menurunkan banyak teknologi dari lini diskrit “Battlemage”. Xe3 meningkatkan kepadatan komputasi, memperlebar unit vektor & matriks, dan memperbesar cache untuk throughput berkelanjutan pada daya serupa. Desainnya skalabel dari 4 Xe cores (Intel 3) hingga 12 Xe cores (TSMC), keduanya terhubung ke compute tile via Foveros fabric berbandwidth tinggi dengan koherensi cache & shared virtual memory.
L2 cache GPU diperluas menjadi 4 MB (4-core) dan 16 MB (12-core) — setara 1 MB/core vs 1,5 MB/core. Tiap Xe3 core mencakup 8 vector engines, 8 matrix engines (XMX), dan 1 RT unit. FP16/INT8 puncak meningkat 2× dari Xe2, membantu rendering tradisional dan tugas AI (denoising, upscaling, frame generation). Unit RT diperbarui (traversal & BVH cache lebih cepat), serta hadir fixed-function blocks baru yang sangat efisien.
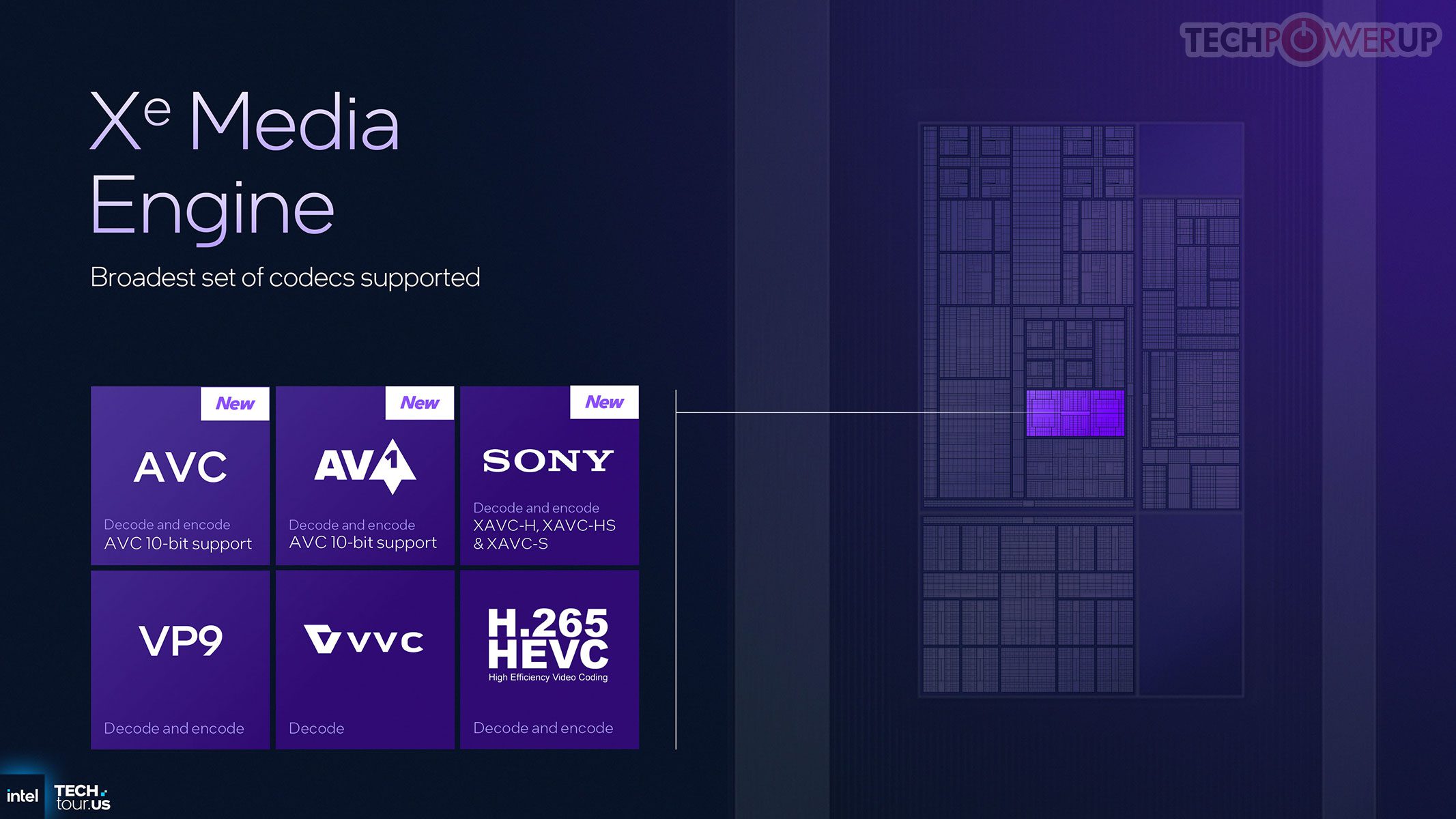
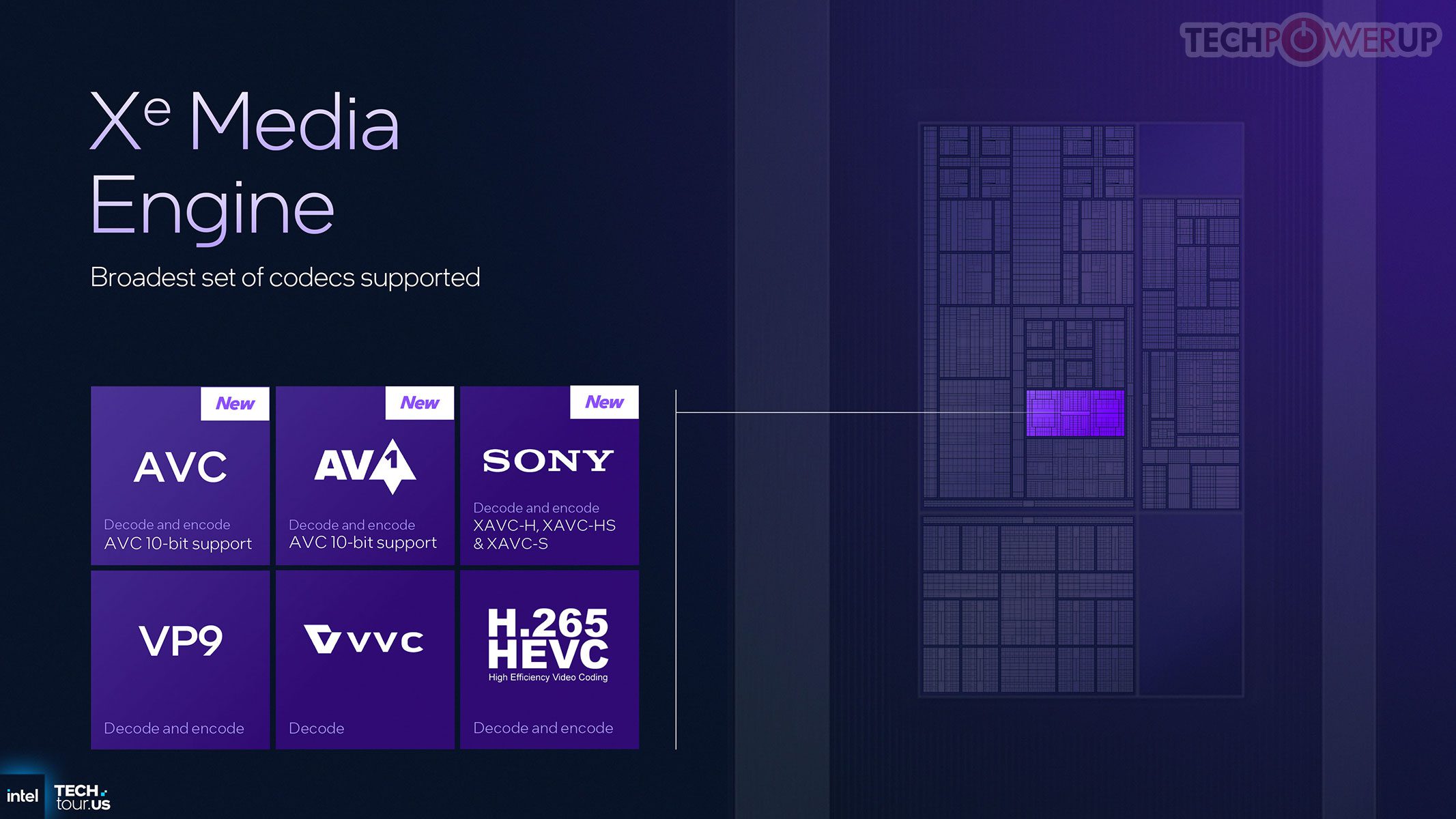
Mesin media menambah dukungan 10-bit AV1/AVC dan format Sony XAVC. XeSS kini menghadirkan multi-frame generation berbasis AI untuk menyintesis frame antar frame asli — menghadirkan feature parity dengan DLSS FG NVIDIA (AMD belum setara). Varian 12-core diklaim ~2× performa GPU Lunar Lake pada daya sebanding; varian 4-core tetap berfitur lengkap namun dioptimalkan untuk efisiensi di laptop tipis.













⏩ Halaman Selanjutnya: Konektivitas Nirkabel & I/O
Konektivitas Nirkabel & I/O
Platform menitikberatkan efisiensi tautan antartile dan ke dunia luar. Platform Controller Tile (PCT) menangani antarmuka eksternal untuk memungkinkan power-gating dan isolasi termal yang lebih baik. PCT mengintegrasikan PCIe Gen 5, USB4, dan dukungan Thunderbolt 5 (via discrete controller opsional — OEM bisa memilih TB4/TB5). Tiap link bisa menurunkan kecepatan dinamis saat idle guna menghemat daya. Storage mendukung NVMe PCIe Gen 5 serta mundur ke Gen 4.
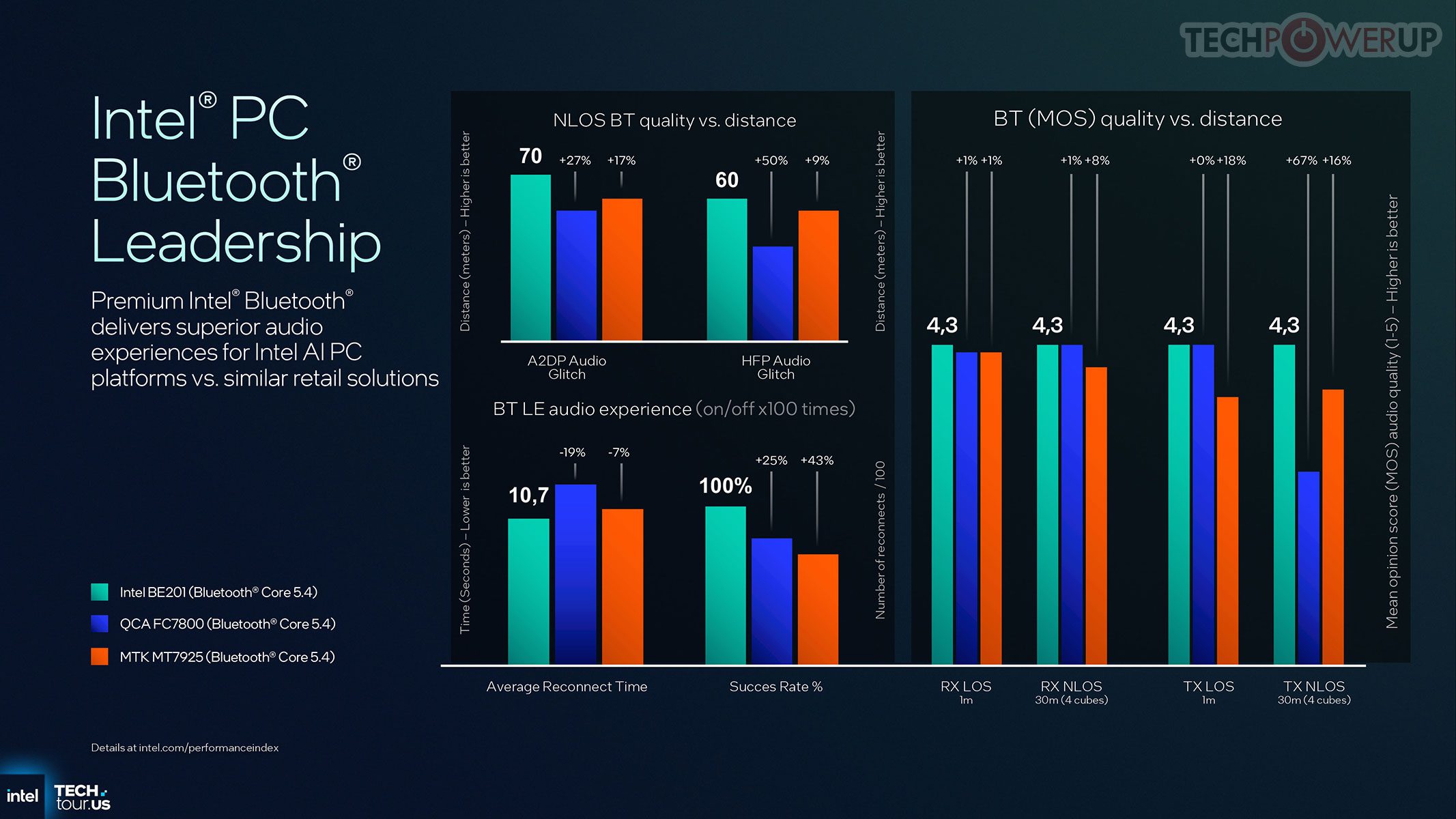
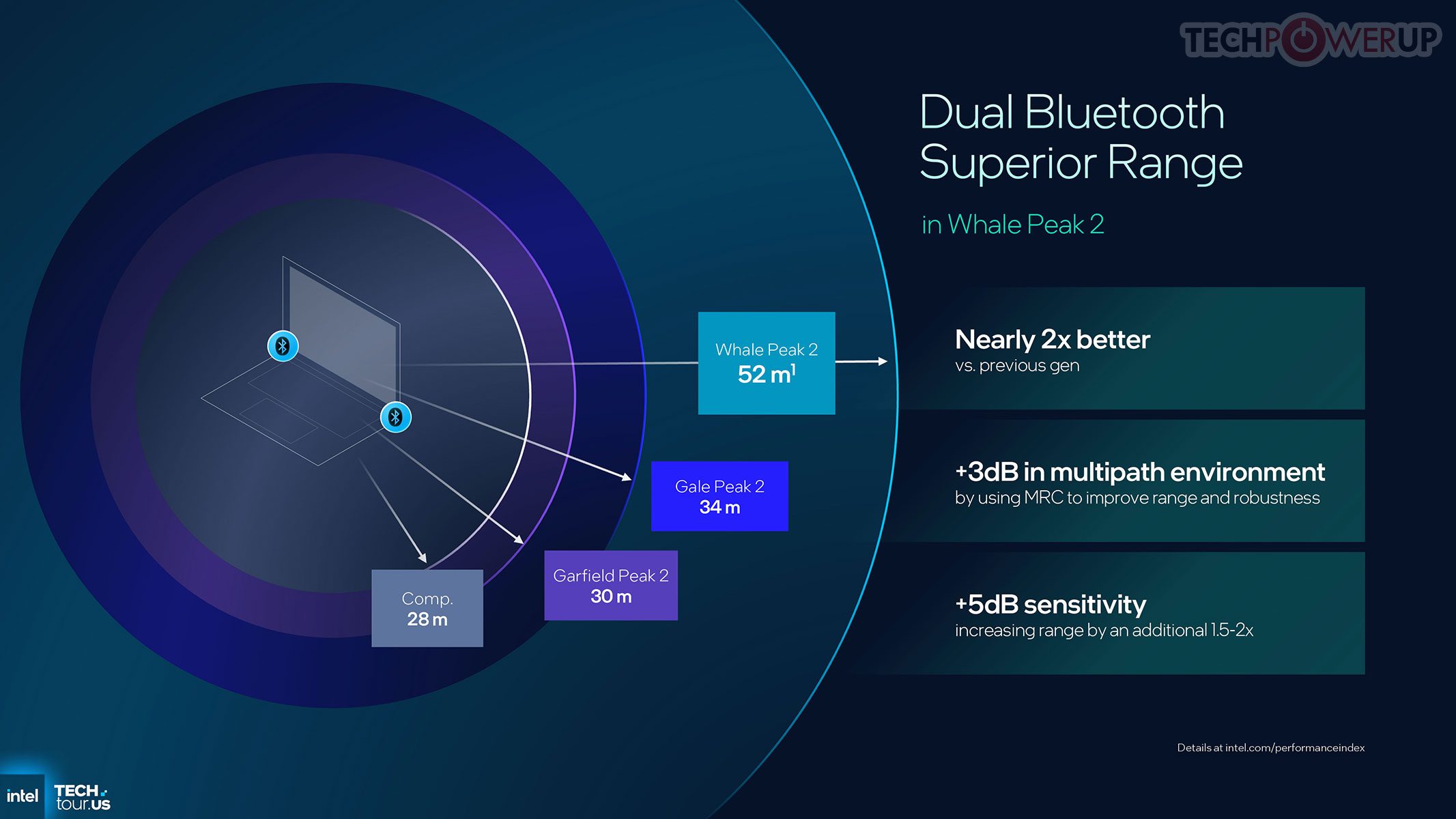
Nirkabel: solusi Wi-Fi 7 (802.11be) terintegrasi penuh dengan Multi-Link Operation dan throughput teoretis hingga ~5 Gbps, mendukung dual-band/tri-band concurrent (2.4/5/6 GHz). Bluetooth 5.4 menyatu dalam modul yang sama, menghemat ruang dan daya dibanding desain dua-chip. Ada dukungan LE Audio (multi-stream, TWS) yang lebih efisien. Fitur Bluetooth 6 Channel Sounding menghadirkan pengukuran jarak presisi (kombinasi RTT & phase-based ranging) dengan akurasi ~10 cm untuk fitur berbasis kedekatan (auto-lock/unlock). Modul Whale Peak 2 memperkenalkan Dual Bluetooth (dua antena) untuk jangkauan nyaris 2× dan +3 dB sensitivitas.








⏩ Halaman Selanjutnya: Integrasi Akselerator AI & Media
Integrasi Akselerator AI & Media
Panther Lake menyatukan blok akselerator AI & media dalam fabric memori koheren yang sama seperti CPU/GPU agar pertukaran data langsung tanpa bolak-balik ke memori sistem — menurunkan latensi & daya. Target Intel: menjadikan AI sebagai kemampuan standar di perangkat arus utama, bukan fitur khusus.
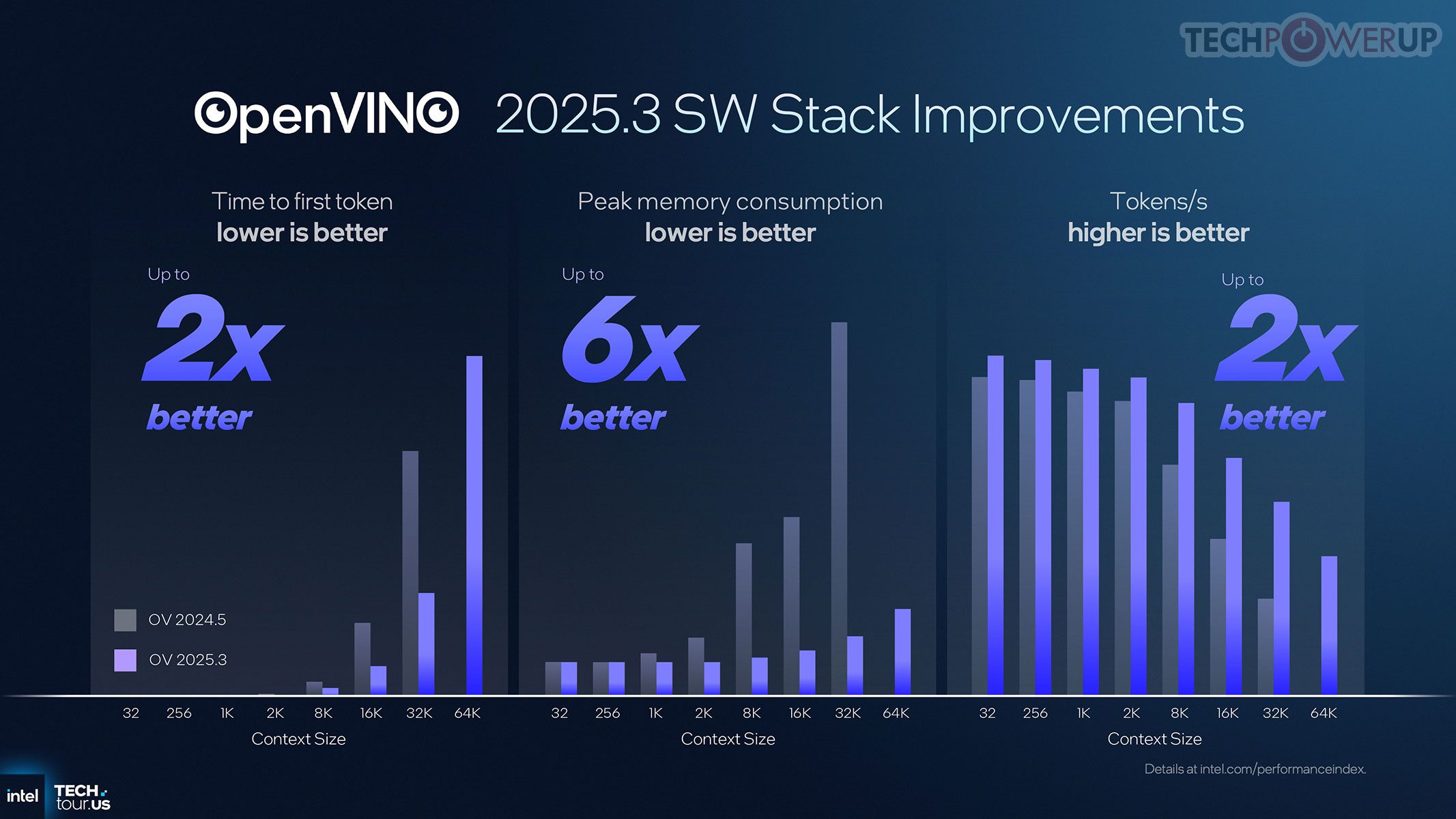
NPU5 menyediakan hingga 48 TOPS — serupa Lunar Lake — namun kini berukuran fisik lebih kecil untuk memangkas biaya. Intel tetap menyertakan NPU di setiap prosesor guna mendorong ekosistem AI on-device. OpenVINO Runtime menjadi lapisan software tunggal untuk mendistribusikan beban AI ke CPU/GPU/NPU, terintegrasi dengan Windows ML, DirectML, dan ONNX Runtime, sehingga aplikasi dapat berskala ke arsitektur Intel mendatang tanpa modifikasi.
IPU 7.5 menangani input kamera/video langsung di SoC, tersambung ke fabric bersama dan memanfaatkan Memory-Side Cache 8 MB sebagai buffer lokal. Ini menurunkan latensi pada alur webcam/rekaman, serta memungkinkan berbagi frame ke GPU/NPU untuk peningkatan visual. Input multi-kamera, HDR capture, dan background segmentation dapat di-offload untuk meminimalkan peran CPU. IPU & NPU berkolaborasi untuk AI-based video enhancement secara real-time dan hemat daya; banyak efek (mis. tone mapping) dapat memilih jalur GPU atau NPU secara dinamis bergantung beban & latensi.
Contoh beban kerja hibrida: noise suppression saat panggilan video, scene detection otomatis, dan AI photo enhancement — IPU untuk input, NPU untuk inferensi, GPU untuk komposisi & tampilan, terkoordinasi melalui memori bersama di bawah layanan AI OS.









⏩ Halaman Selanjutnya: Peningkatan Terukur & Klaim Keunggulan
Peningkatan Terukur & Klaim Keunggulan
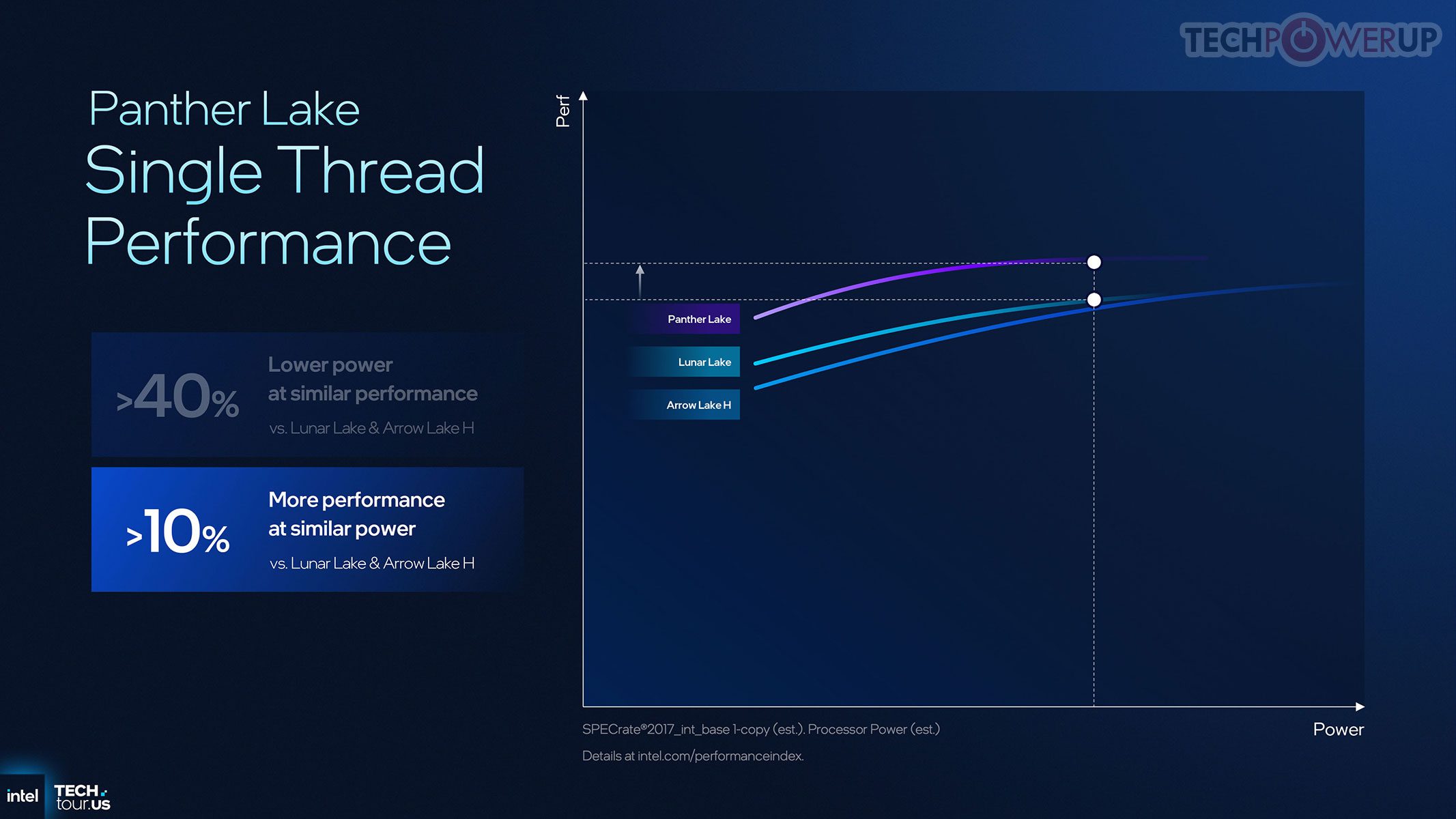
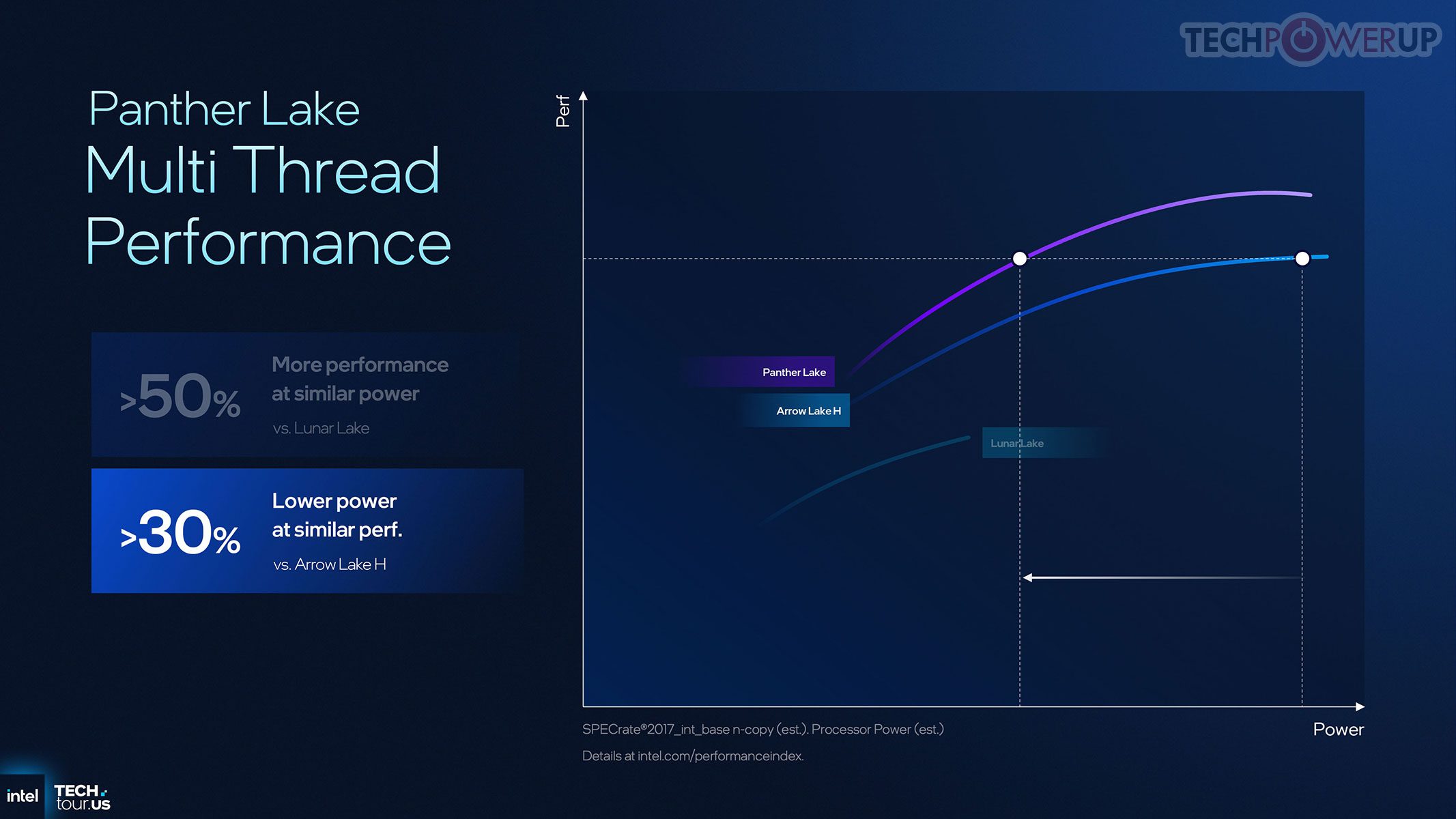
Intel memosisikan Panther Lake sebagai lompatan generasi penuh dari Lunar Lake dalam throughput dan efisiensi daya. Klaim internal: hingga +10% performa single-thread pada daya sama, dan +50% multithread pada daya sebanding — implikasinya, daya jauh lebih rendah untuk beban kerja yang sama di beragam aplikasi.
Cougar Cove P-core membawa per-core uplift dan skalabilitas lebih baik saat dibebani, sementara Darkmont E-core mencapai hingga +50% performa pada daya sama — meningkatkan efisiensi dan responsivitas, khususnya pada multitasking/tugas latar. Darkmont bahkan diklaim melampaui Raptor Cove sambil berada dalam batas daya lebih ketat — menegaskan fokus efisiensi tanpa mengorbankan performa mentah.
Xe3 iGPU 12-core diklaim +50% lebih cepat dari GPU Lunar Lake dan +40% lebih efisien/W dibanding Arrow Lake-H; performa gaming pada daya rendah meningkat nyata. NPU yang lebih kecil membebaskan area untuk komponen lain; dukungan INT8 meningkatkan kecepatan, menghemat memori & daya untuk beban tertentu. Konektivitas nirkabel diklaim jangkauannya lebih baik dari kompetitor; Wi-Fi 7 membuka opsi bandwidth tinggi atau perpanjangan jangkauan. Beragam optimasi platform memastikan distribusi energi lebih adil lintas unit sehingga tiap blok hardware dapat bekerja optimal tanpa power starvation.
Kesimpulan: Dengan kombinasi efisiensi, skalabilitas, fabric koheren, GPU Xe3, dan akselerator AI yang terintegrasi, Panther Lake berpotensi menjadi tonggak besar untuk lini mobile Intel — mengutamakan performa berkelanjutan dalam power envelope mobile alih-alih hanya mengejar frekuensi puncak.










⏩ Halaman Selanjutnya: Kesimpulan: Melangkah ke Uji Dunia Nyata Panther Lake
Kesimpulan — Melangkah ke Uji Dunia Nyata Panther Lake
Langkah Besar di Atas Kertas
Panther Lake adalah platform klien Intel yang paling terpadu secara teknis sejauh ini — menggabungkan teknologi proses terbaru, arsitektur yang disempurnakan, serta strategi multi-die packaging ke dalam satu keluarga produk.
Transisi ke proses Intel 18A dengan RibbonFET dan PowerVia menjanjikan peningkatan performa sekaligus efisiensi daya yang jauh lebih baik.
Ini menjadi chip klien pertama yang sepenuhnya memanfaatkan kemampuan manufaktur paling maju Intel, sekaligus panggung showcase bagi lini bisnis Intel Foundry Services yang tengah berusaha menarik pelanggan baru.
Namun, seperti pengalaman pada Arrow Lake, spesifikasi di atas kertas tidak selalu berbanding lurus dengan performa dunia nyata — kita perlu menunggu produk finalnya beredar untuk benar-benar menilai hasilnya.
Evolusi Core dan Fabric
Intel memperkenalkan kombinasi Cougar Cove P-Core dan Darkmont E-Core yang terhubung melalui fabric koheren generasi baru, memungkinkan GPU, NPU, dan IPU berbagi memori langsung tanpa hambatan.
Tambahan Low-Power E-Core tampak menjanjikan untuk menangani beban ringan di latar belakang dengan efisien.
Serangkaian penyempurnaan arsitektur seperti dispatch lebih lebar, prediksi cabang lebih cerdas, dan penjadwalan yang dioptimalkan menunjukkan fokus Intel untuk memberikan performa stabil baik pada beban singkat maupun jangka panjang.
Penempatan pengendali memori di tile yang sama dengan compute-core juga diperkirakan menurunkan latensi dibanding desain Arrow Lake sebelumnya.
Fitur baru seperti Memory-Side Cache pun menjadi komponen yang menarik untuk diamati penggunaannya saat prosesor ini resmi diluncurkan.
Thread Director yang Lebih Pintar
Selain perubahan arsitektur, Intel juga memperbarui Thread Director agar lebih cermat memantau perilaku workload dan mengambil keputusan penjadwalan yang optimal.
Kebijakan penjadwalan default pun diubah untuk menyesuaikan dengan pola beban kerja pengguna umum.
Klaim efisiensi serta responsivitas yang dijanjikan Intel di area ini terdengar sangat menjanjikan, terutama bagi sistem mobile.
Integrasi Grafis, AI, dan Media
GPU Xe3 Celestial menawarkan lompatan performa besar dibanding Lunar Lake, yang sebelumnya sudah cukup kompetitif untuk laptop dan handheld.
Kini hadir dukungan penuh untuk XeSS Upscaling serta fitur baru Frame Generation dan Multi-Frame Generation — menjadikan Intel sejajar dengan pesaing besar di ranah grafis terintegrasi.
Dengan hingga 12 Xe Core dan 16 MB L2 Cache, GPU terintegrasi ini mendekati performa GPU diskrit kelas awal.
Sementara itu, NPU 5.0 mempertahankan throughput sekitar 48 TOPS dengan ukuran die lebih kecil, menurunkan biaya produksi di saat adopsi NPU konsumen masih terbatas.
Intel pun mengakui adanya chicken-and-egg problem pada akselerasi AI: developer membutuhkan hardware yang tersedia luas sebelum berani membuat software yang bergantung padanya.
Dukungan dari media engine dan IPU 7.5 memperkuat integrasi AI pada video — mulai dari peningkatan kualitas gambar, penghilangan noise, hingga pemrosesan latar belakang secara real-time di perangkat.
Intel 18A: Kekuatan dan Ketidakpastian
Walau 18A menjadi pusat inovasi Panther Lake, ia juga membawa tantangan tersendiri.
Sebagai node proses baru, faktor yield dan variabilitas masih bisa menjadi risiko pada tahap awal produksi.
Untungnya, penggunaan desain chiplet kecil via Foveros membantu meningkatkan yield dan menekan cacat produksi.
Kini semua komponen penting seolah menyatu tepat waktu untuk membentuk generasi CPU baru, namun keunggulan 18A harus terbukti dalam produksi volume besar yang stabil sebelum Intel dapat mengklaim keberhasilan penuh.
Optimisme yang Hati-Hati Setelah Arrow Lake
Arrow Lake (khusus desktop) sempat diharapkan menjadi terobosan besar, tetapi hasil akhirnya kurang sesuai ekspektasi.
Panther Lake terlihat lebih matang di atas kertas — dengan penjadwalan hybrid yang lebih baik, fabric lebih cepat, dan penyempurnaan arsitektur nyata — namun validasi dunia nyata akan menjadi penentu apakah janji itu terpenuhi.
Intel tampak percaya diri, meski belum menampilkan angka performa final, yang memang wajar untuk tahap prapeluncuran seperti ini.
Lanskap Persaingan
Intel akan menghadapi kompetisi pasar yang makin ketat saat Panther Lake dirilis.
NVIDIA sedang mengembangkan prosesor Arm-based untuk laptop Windows dengan GPU terintegrasi yang dapat mendefinisikan ulang efisiensi performa-per-watt di segmen premium.
Qualcomm juga menyiapkan generasi Snapdragon baru, meski masih tertinggal dalam tumpukan perangkat lunak GPU.
Sementara Apple tetap menjadi lawan tangguh dengan integrasi menyeluruh antara perangkat keras dan perangkat lunak pada chip seri M-nya.
Waktu Peluncuran dan Ketersediaan
Intel berencana memperkenalkan sistem berbasis Panther Lake pada CES 2026 di Las Vegas.
Notebook komersial diharapkan mulai dikirim pada kuartal pertama 2026.
Sepanjang sisa tahun 2025, Intel dan mitra OEM-nya akan fokus pada validasi desain serta penyesuaian daya dan termal.
Akan menarik untuk melihat bagaimana posisi Arrow Lake Mobile nantinya, karena berbagai konfigurasi Panther Lake tampaknya sudah cukup mencakup hampir seluruh pasar notebook modern.
🌟 Ringkasan Akhir
Panther Lake mewakili babak baru dalam evolusi prosesor Intel — menyatukan inovasi manufaktur, arsitektur hybrid yang disempurnakan, serta akselerator AI terpadu.
Jika semua janji di atas kertas dapat terwujud pada produk final, Intel berpeluang kembali memimpin persaingan di ranah mobile melalui kombinasi efisiensi, daya tahan baterai, dan performa komputasi yang seimbang.
💬 Kata penutup:
Panther Lake mungkin belum terbukti di dunia nyata, tetapi ia menjadi simbol bahwa Intel kini benar-benar siap memasuki era baru komputasi mobile yang berpusat pada efisiensi, AI, dan desain modular.